 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCDP-SGD: Improving the Convergence of Differentially Private SGD via Projection in Advance
Paper and Code
Dec 06, 2023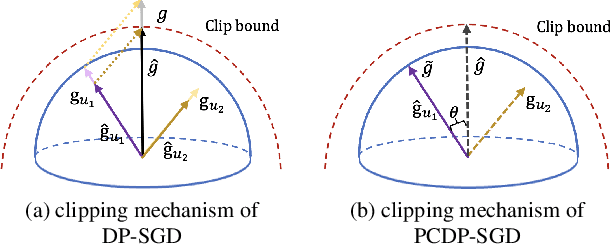


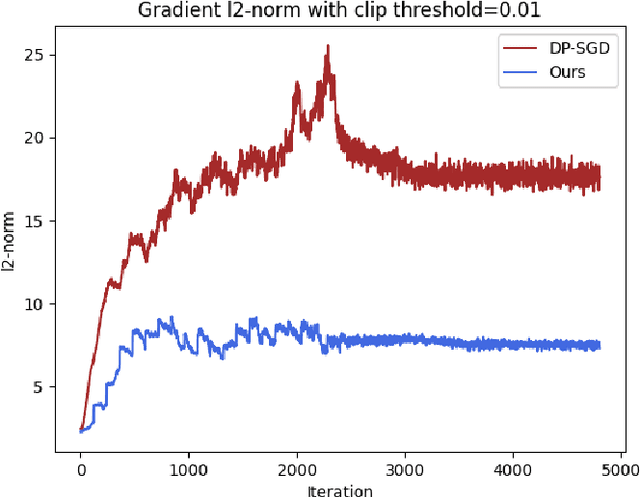
The paradigm of Differentially Private SGD~(DP-SGD) can provide a theoretical guarantee for training data in both centralized and federated settings. However, the utility degradation caused by DP-SGD limits its wide application in high-stakes tasks, such as medical image diagnosis. In addition to the necessary perturbation, the convergence issue is attributed to the information loss on the gradient clipping. In this work, we propose a general framework PCDP-SGD, which aims to compress redundant gradient norms and preserve more crucial top gradient components via projection operation before gradient clipping. Additionally, we extend PCDP-SGD as a fundamental component in differential privacy federated learning~(DPFL) for mitigating the data heterogeneous challenge and achieving efficient communication. We prove that pre-projection enhances the convergence of DP-SGD by reducing the dependence of clipping error and bias to a fraction of the top gradient eigenspace, and in theory, limits cross-client variance to improve the convergence under heterogeneous federation. Experimental results demonstrate that PCDP-SGD achieves higher accuracy compared with state-of-the-art DP-SGD variants in computer vision tasks. Moreover, PCDP-SGD outperforms current federated learning frameworks when DP is guaranteed on local training sets.