 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Efficiency and Effectiveness: An LLM-Infused Approach for Optimized CTR Prediction
Dec 09, 2024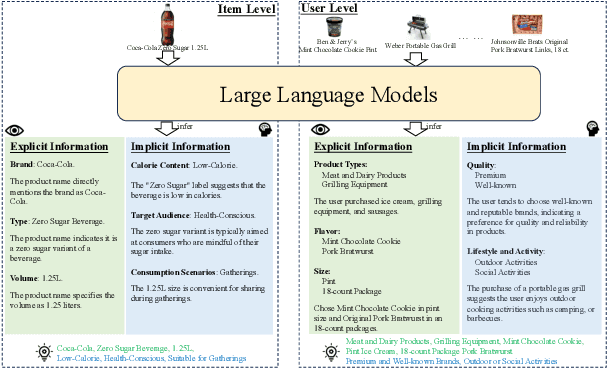

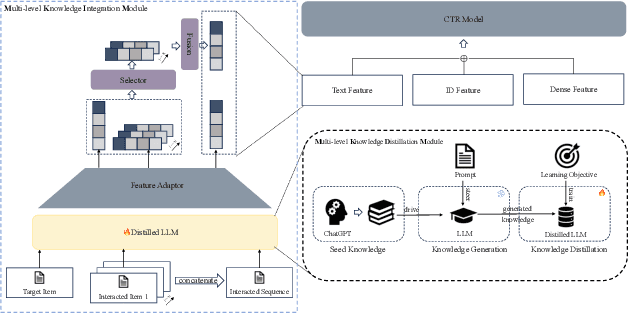

Click-Through Rate (CTR) prediction is essential in online advertising, where semantic information plays a pivotal role in shaping user decisions and enhancing CTR effectiveness. Capturing and modeling deep semantic information, such as a user's preference for "H\"aagen-Dazs' HEAVEN strawberry light ice cream" due to its health-conscious and premium attributes, is challenging. Traditional semantic modeling often overlooks these intricate details at the user and item levels. To bridge this gap, we introduce a novel approach that models deep semantic information end-to-end, leveraging the comprehensive world knowledge capabilities of Large Language Models (LLMs). Our proposed LLM-infused CTR prediction framework(Multi-level Deep Semantic Information Infused CTR model via Distillation, MSD) is designed to uncover deep semantic insights by utilizing LLMs to extract and distill critical information into a smaller, more efficient model, enabling seamless end-to-end training and inference. Importantly, our framework is carefully designed to balance efficiency and effectiveness, ensuring that the model not only achieves high performance but also operates with optimal resource utilization. Online A/B tests conducted on the Meituan sponsored-search system demonstrate that our method significantly outperforms baseline models in terms of Cost Per Mile (CPM) and CTR, validating its effectiveness, scalability, and balanced approach in real-world applications.
EGEAN: An Exposure-Guided Embedding Alignment Network for Post-Click Conversion Estimation
Dec 08, 2024



Accurate post-click conversion rate (CVR) estimation is crucial for online advertising systems. Despite significant advances in causal approaches designed to address the Sample Selection Bias problem, CVR estimation still faces challenges due to Covariate Shift. Given the intrinsic connection between the distribution of covariates in the click and non-click spaces, this study proposes an Exposure-Guided Embedding Alignment Network (EGEAN) to address estimation bias caused by covariate shift. Additionally, we propose a Parameter Varying Doubly Robust Estimator with steady-state control to handle small propensities better. Online A/B tests conducted on the Meituan advertising system demonstrate that our method significantly outperforms baseline models with respect to CVR and GMV, validating its effectiveness. Code is available: https://github.com/hydrogen-maker/EGEAN.
StackRec: Efficient Training of Very Deep Sequential Recommender Models by Layer Stacking
Dec 14, 2020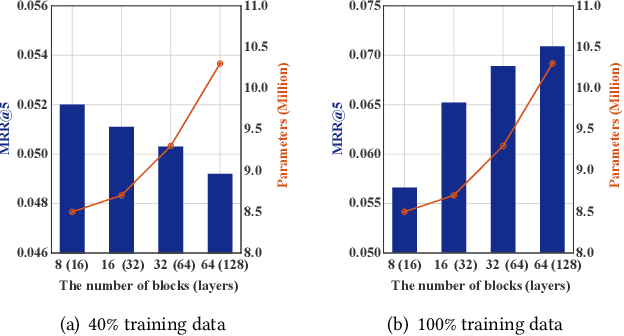
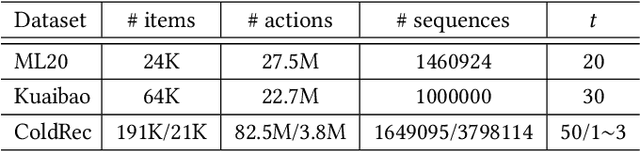
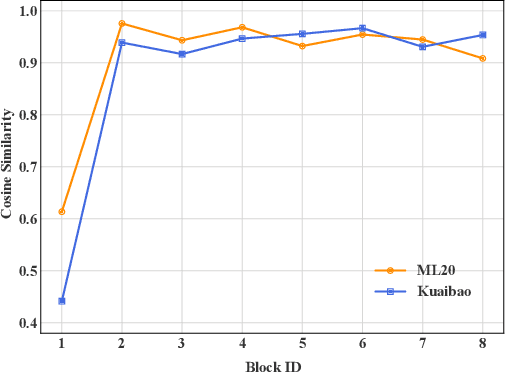
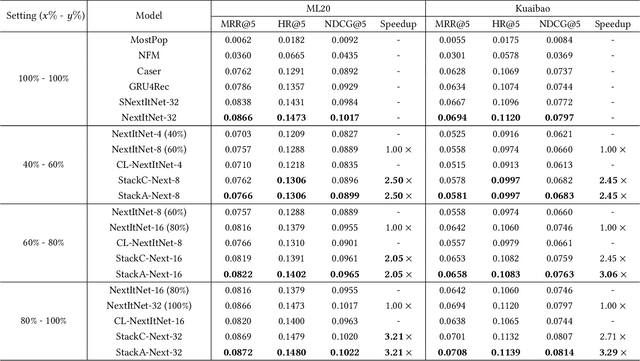
Deep learning has brought great progress for the sequential recommendation (SR) tasks. With the structure of advanced residual networks, sequential recommender models can be stacked with many hidden layers, e.g., up to 100 layers on real-world SR datasets. Training such a deep network requires expensive computation and longer training time, especially in situations when there are tens of billions of user-item interactions. To deal with such a challenge, we present StackRec, a simple but very efficient training framework for deep SR models by layer stacking. Specifically, we first offer an important insight that residual layers/blocks in a well-trained deep SR model have similar distribution. Enlightened by this, we propose progressively stacking such pre-trained residual layers/blocks so as to yield a deeper but easier-to-train SR model. We validate the proposed StackRec by instantiating with two state-of-the-art SR models in three practical scenarios and real-world datasets. Extensive experiments show that StackRec achieves not only comparable performance, but also significant acceleration in training time, compared to SR models that are trained from scratch.