 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStackRec: Efficient Training of Very Deep Sequential Recommender Models by Layer Stacking
Dec 14, 2020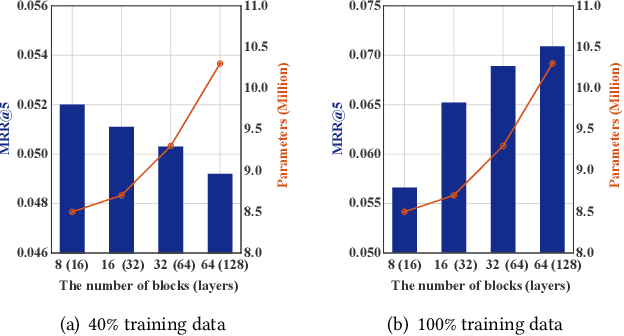
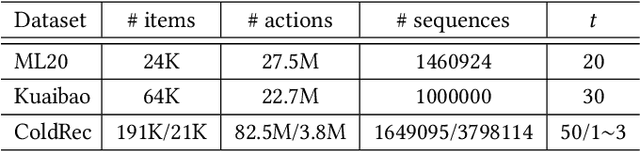
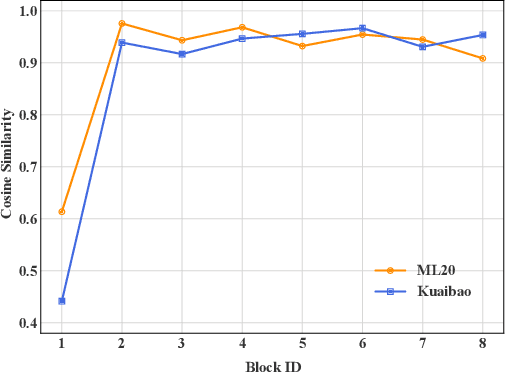
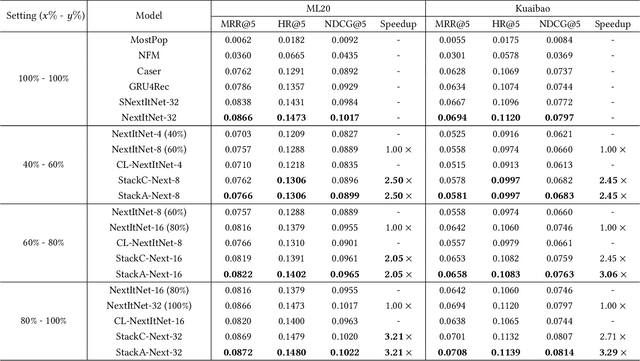
Deep learning has brought great progress for the sequential recommendation (SR) tasks. With the structure of advanced residual networks, sequential recommender models can be stacked with many hidden layers, e.g., up to 100 layers on real-world SR datasets. Training such a deep network requires expensive computation and longer training time, especially in situations when there are tens of billions of user-item interactions. To deal with such a challenge, we present StackRec, a simple but very efficient training framework for deep SR models by layer stacking. Specifically, we first offer an important insight that residual layers/blocks in a well-trained deep SR model have similar distribution. Enlightened by this, we propose progressively stacking such pre-trained residual layers/blocks so as to yield a deeper but easier-to-train SR model. We validate the proposed StackRec by instantiating with two state-of-the-art SR models in three practical scenarios and real-world datasets. Extensive experiments show that StackRec achieves not only comparable performance, but also significant acceleration in training time, compared to SR models that are trained from scratch.