 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Fully Convolution Neural Network for Generating Pixel Wise Robotic Grasps With High Resolution Images
Paper and Code
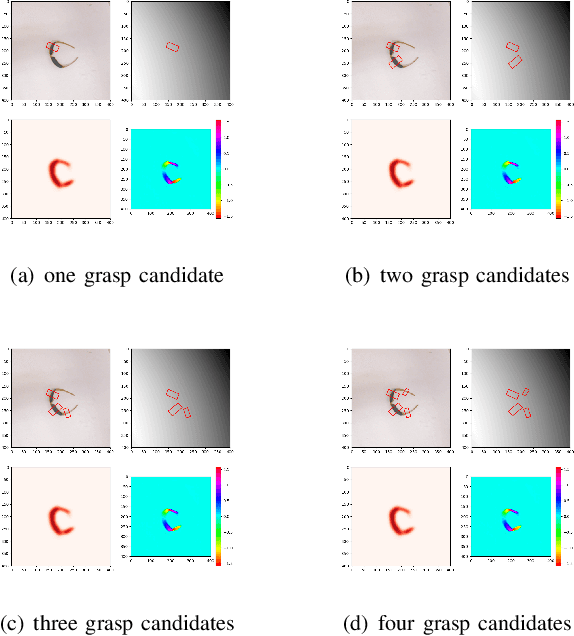

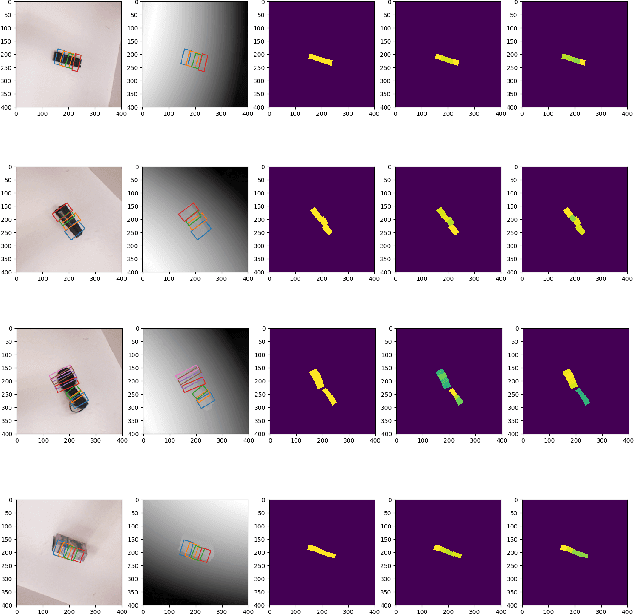
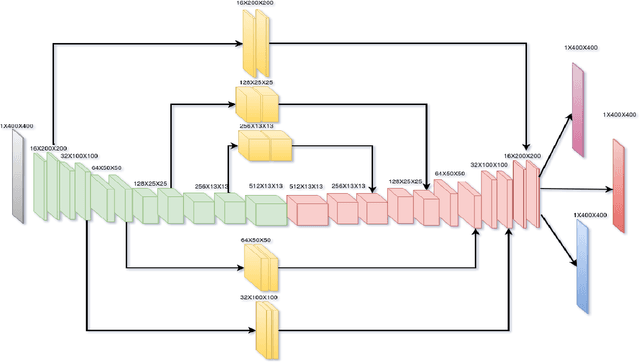
This paper presents an efficient neural network model to generate robotic grasps with high resolution images. The proposed model uses fully convolution neural network to generate robotic grasps for each pixel using 400 $\times$ 400 high resolution RGB-D images. It first down-sample the images to get features and then up-sample those features to the original size of the input as well as combines local and global features from different feature maps. Compared to other regression or classification methods for detecting robotic grasps, our method looks more like the segmentation methods which solves the problem through pixel-wise ways. We use Cornell Grasp Dataset to train and evaluate the model and get high accuracy about 94.42% for image-wise and 91.02% for object-wise and fast prediction time about 8ms. We also demonstrate that without training on the multiple objects dataset, our model can directly output robotic grasps candidates for different objects because of the pixel wise implementation.