 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Prediction Under Generalized Covariate Shift with Posterior Drift
Feb 25, 2025



In many real applications of statistical learning, collecting sufficiently many training data is often expensive, time-consuming, or even unrealistic. In this case, a transfer learning approach, which aims to leverage knowledge from a related source domain to improve the learning performance in the target domain, is more beneficial. There have been many transfer learning methods developed under various distributional assumptions. In this article, we study a particular type of classification problem, called conformal prediction, under a new distributional assumption for transfer learning. Classifiers under the conformal prediction framework predict a set of plausible labels instead of one single label for each data instance, affording a more cautious and safer decision. We consider a generalization of the \textit{covariate shift with posterior drift} setting for transfer learning. Under this setting, we propose a weighted conformal classifier that leverages both the source and target samples, with a coverage guarantee in the target domain. Theoretical studies demonstrate favorable asymptotic properties. Numerical studies further illustrate the usefulness of the proposed method.
Conformal Inference of Individual Treatment Effects Using Conditional Density Estimates
Jan 24, 2025In an era where diverse and complex data are increasingly accessible, the precise prediction of individual treatment effects (ITE) becomes crucial across fields such as healthcare, economics, and public policy. Current state-of-the-art approaches, while providing valid prediction intervals through Conformal Quantile Regression (CQR) and related techniques, often yield overly conservative prediction intervals. In this work, we introduce a conformal inference approach to ITE using the conditional density of the outcome given the covariates. We leverage the reference distribution technique to efficiently estimate the conditional densities as the score functions under a two-stage conformal ITE framework. We show that our prediction intervals are not only marginally valid but are narrower than existing methods. Experimental results further validate the usefulness of our method.
Efficient Online Set-valued Classification with Bandit Feedback
May 07, 2024

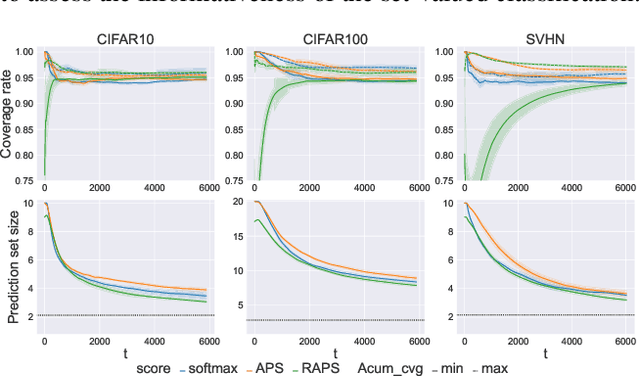
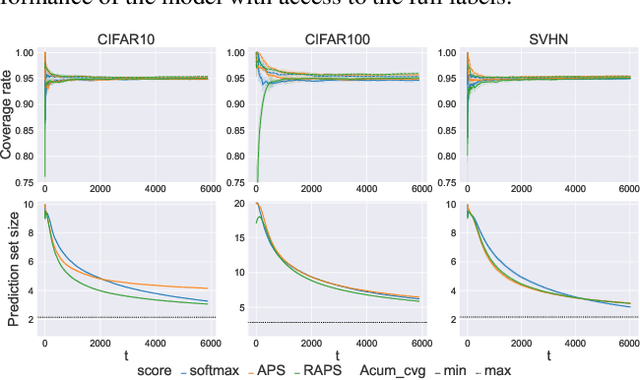
Conformal prediction is a distribution-free method that wraps a given machine learning model and returns a set of plausible labels that contain the true label with a prescribed coverage rate. In practice, the empirical coverage achieved highly relies on fully observed label information from data both in the training phase for model fitting and the calibration phase for quantile estimation. This dependency poses a challenge in the context of online learning with bandit feedback, where a learner only has access to the correctness of actions (i.e., pulled an arm) but not the full information of the true label. In particular, when the pulled arm is incorrect, the learner only knows that the pulled one is not the true class label, but does not know which label is true. Additionally, bandit feedback further results in a smaller labeled dataset for calibration, limited to instances with correct actions, thereby affecting the accuracy of quantile estimation. To address these limitations, we propose Bandit Class-specific Conformal Prediction (BCCP), offering coverage guarantees on a class-specific granularity. Using an unbiased estimation of an estimand involving the true label, BCCP trains the model and makes set-valued inferences through stochastic gradient descent. Our approach overcomes the challenges of sparsely labeled data in each iteration and generalizes the reliability and applicability of conformal prediction to online decision-making environments.
Learning Acceptance Regions for Many Classes with Anomaly Detection
Sep 20, 2022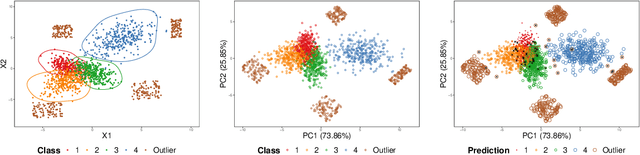
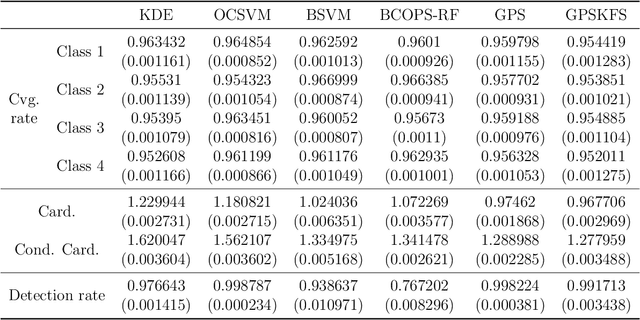
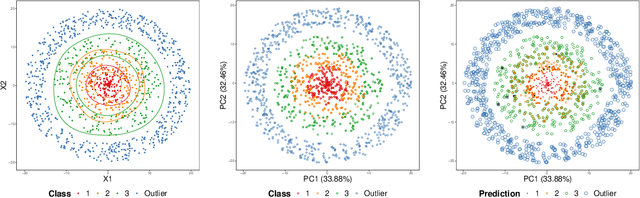
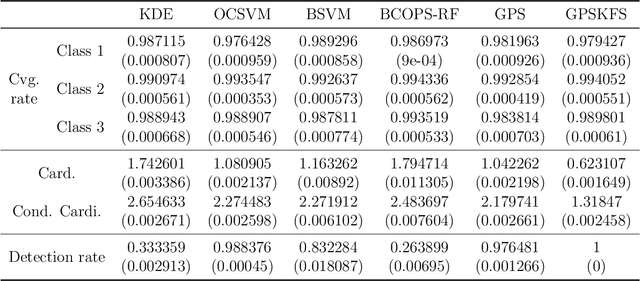
Set-valued classification, a new classification paradigm that aims to identify all the plausible classes that an observation belongs to, can be obtained by learning the acceptance regions for all classes. Many existing set-valued classification methods do not consider the possibility that a new class that never appeared in the training data appears in the test data. Moreover, they are computationally expensive when the number of classes is large. We propose a Generalized Prediction Set (GPS) approach to estimate the acceptance regions while considering the possibility of a new class in the test data. The proposed classifier minimizes the expected size of the prediction set while guaranteeing that the class-specific accuracy is at least a pre-specified value. Unlike previous methods, the proposed method achieves a good balance between accuracy, efficiency, and anomaly detection rate. Moreover, our method can be applied in parallel to all the classes to alleviate the computational burden. Both theoretical analysis and numerical experiments are conducted to illustrate the effectiveness of the proposed method.
Enhanced Nearest Neighbor Classification for Crowdsourcing
Feb 26, 2022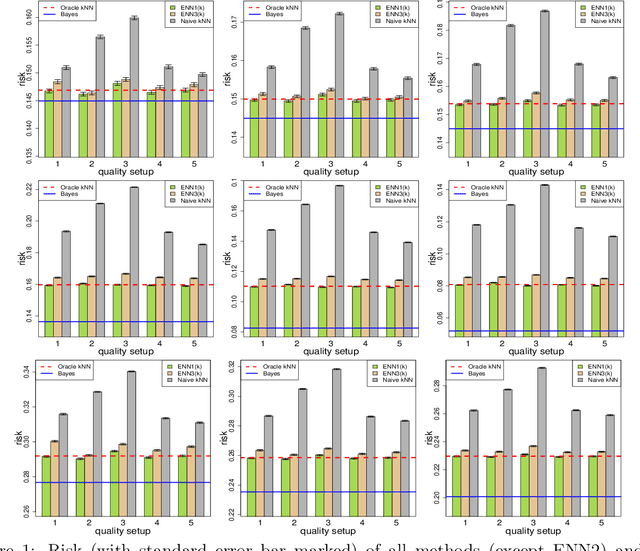
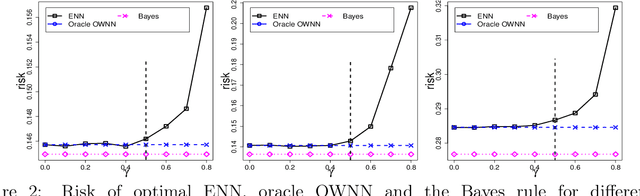
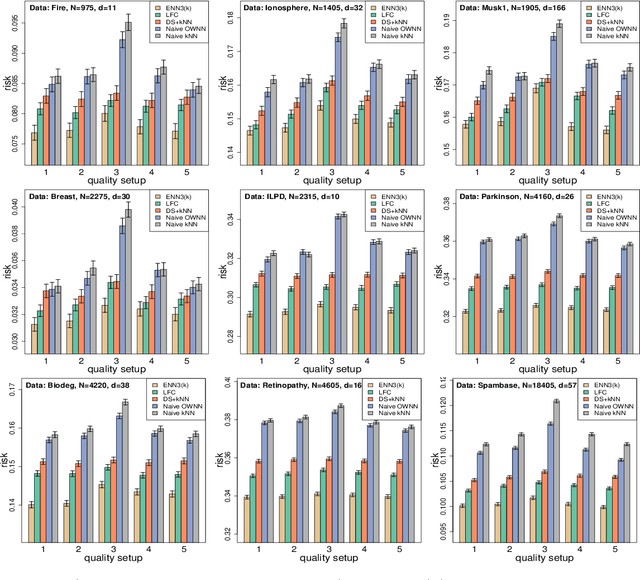
In machine learning, crowdsourcing is an economical way to label a large amount of data. However, the noise in the produced labels may deteriorate the accuracy of any classification method applied to the labelled data. We propose an enhanced nearest neighbor classifier (ENN) to overcome this issue. Two algorithms are developed to estimate the worker quality (which is often unknown in practice): one is to construct the estimate based on the denoised worker labels by applying the $k$NN classifier to the expert data; the other is an iterative algorithm that works even without access to the expert data. Other than strong numerical evidence, our proposed methods are proven to achieve the same regret as its oracle version based on high-quality expert data. As a technical by-product, a lower bound on the sample size assigned to each worker to reach the optimal convergence rate of regret is derived.
Covariance-engaged Classification of Sets via Linear Programming
Jun 26, 2020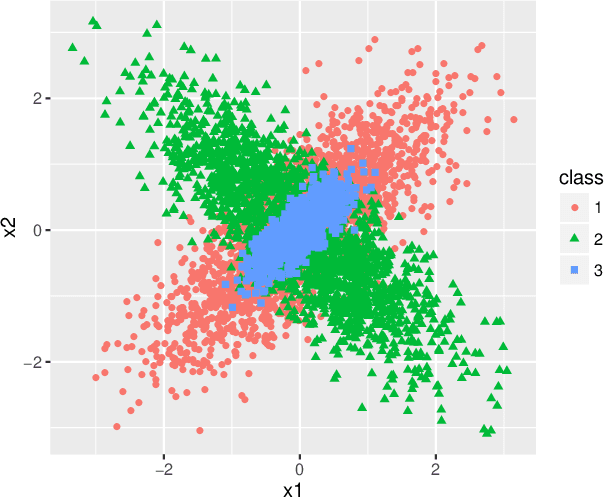
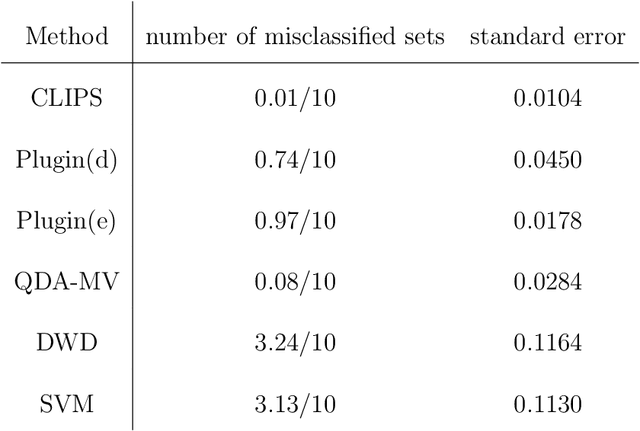
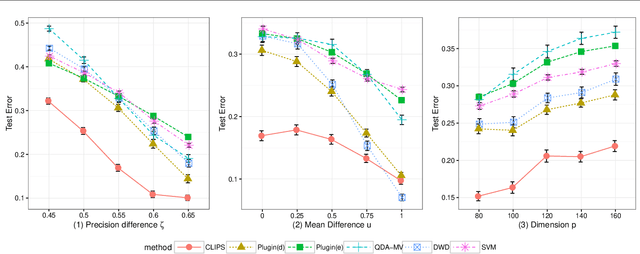
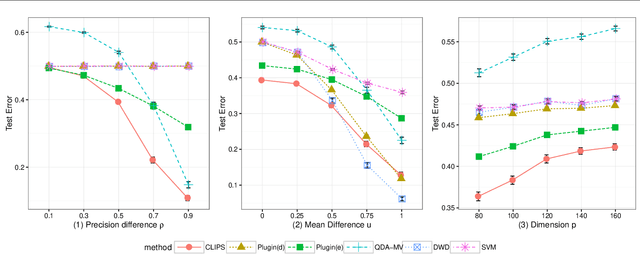
Set classification aims to classify a set of observations as a whole, as opposed to classifying individual observations separately. To formally understand the unfamiliar concept of binary set classification, we first investigate the optimal decision rule under the normal distribution, which utilizes the empirical covariance of the set to be classified. We show that the number of observations in the set plays a critical role in bounding the Bayes risk. Under this framework, we further propose new methods of set classification. For the case where only a few parameters of the model drive the difference between two classes, we propose a computationally-efficient approach to parameter estimation using linear programming, leading to the Covariance-engaged LInear Programming Set (CLIPS) classifier. Its theoretical properties are investigated for both independent case and various (short-range and long-range dependent) time series structures among observations within each set. The convergence rates of estimation errors and risk of the CLIPS classifier are established to show that having multiple observations in a set leads to faster convergence rates, compared to the standard classification situation in which there is only one observation in the set. The applicable domains in which the CLIPS performs better than competitors are highlighted in a comprehensive simulation study. Finally, we illustrate the usefulness of the proposed methods in classification of real image data in histopathology.
Near-optimal Individualized Treatment Recommendations
Apr 06, 2020
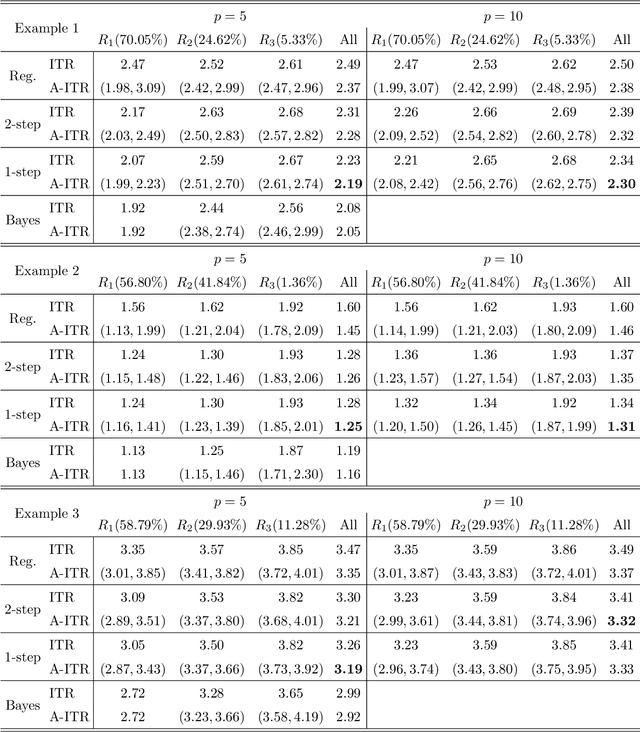
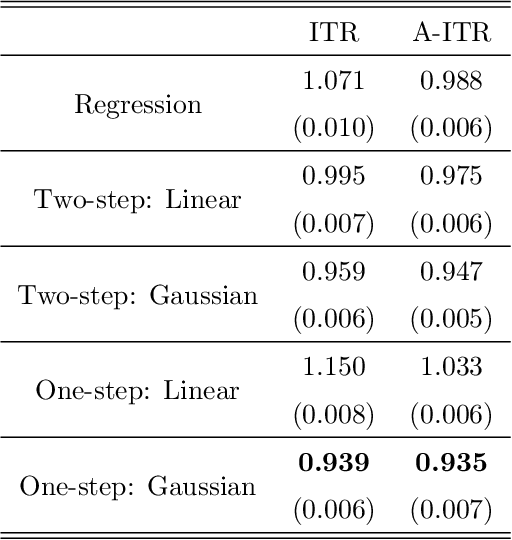
Individualized treatment recommendation (ITR) is an important analytic framework for precision medicine. The goal is to assign proper treatments to patients based on their individual characteristics. From the machine learning perspective, the solution to an ITR problem can be formulated as a weighted classification problem to maximize the average benefit that patients receive from the recommended treatments. Several methods have been proposed for ITR in both binary and multicategory treatment setups. In practice, one may prefer a more flexible recommendation with multiple treatment options. This motivates us to develop methods to obtain a set of near-optimal individualized treatment recommendations alternative to each other, called alternative individualized treatment recommendations (A-ITR). We propose two methods to estimate the optimal A-ITR within the outcome weighted learning (OWL) framework. We show the consistency of these methods and obtain an upper bound for the risk between the theoretically optimal recommendation and the estimated one. We also conduct simulation studies, and apply our methods to a real data set for Type 2 diabetic patients with injectable antidiabetic treatments. These numerical studies have shown the usefulness of the proposed A-ITR framework. We develop a R package aitr which can be found at https://github.com/menghaomiao/aitr.
Maximum Entropy Diverse Exploration: Disentangling Maximum Entropy Reinforcement Learning
Nov 03, 2019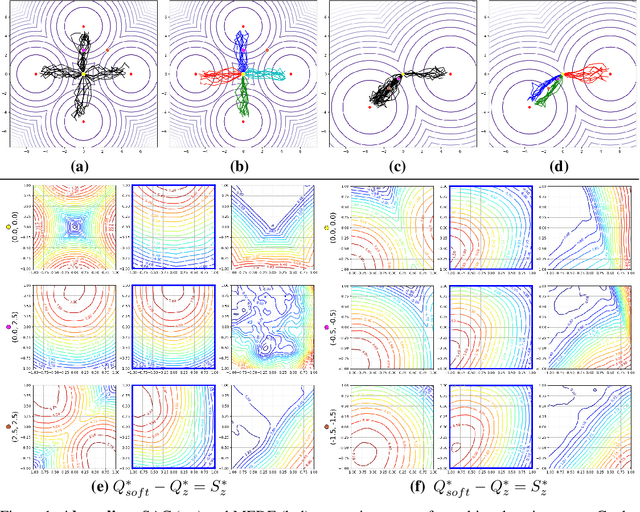
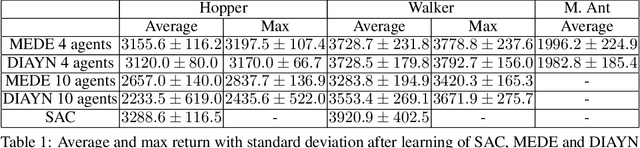
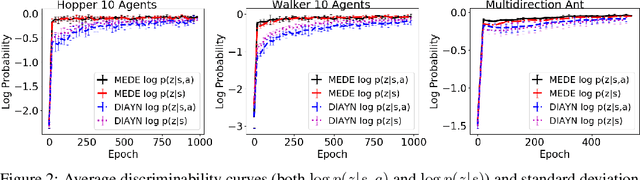
Two hitherto disconnected threads of research, diverse exploration (DE) and maximum entropy RL have addressed a wide range of problems facing reinforcement learning algorithms via ostensibly distinct mechanisms. In this work, we identify a connection between these two approaches. First, a discriminator-based diversity objective is put forward and connected to commonly used divergence measures. We then extend this objective to the maximum entropy framework and propose an algorithm Maximum Entropy Diverse Exploration (MEDE) which provides a principled method to learn diverse behaviors. A theoretical investigation shows that the set of policies learned by MEDE capture the same modalities as the optimal maximum entropy policy. In effect, the proposed algorithm disentangles the maximum entropy policy into its diverse, constituent policies. Experiments show that MEDE is superior to the state of the art in learning high performing and diverse policies.
Rates of Convergence for Large-scale Nearest Neighbor Classification
Sep 03, 2019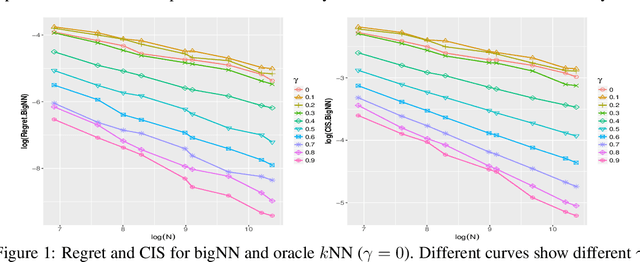
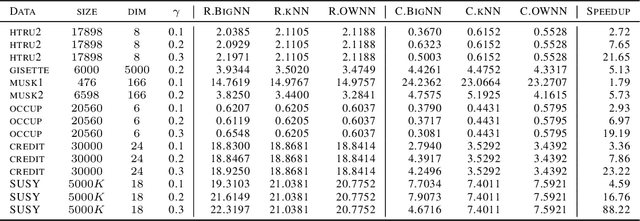
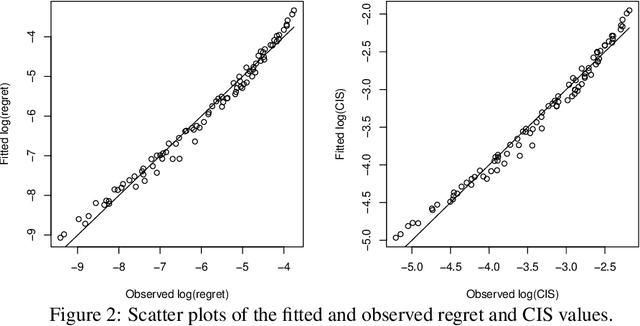
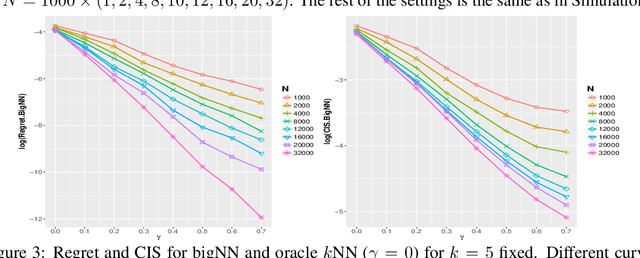
Nearest neighbor is a popular class of classification methods with many desirable properties. For a large data set which cannot be loaded into the memory of a single machine due to computation, communication, privacy, or ownership limitations, we consider the divide and conquer scheme: the entire data set is divided into small subsamples, on which nearest neighbor predictions are made, and then a final decision is reached by aggregating the predictions on subsamples by majority voting. We name this method the big Nearest Neighbor (bigNN) classifier, and provide its rates of convergence under minimal assumptions, in terms of both the excess risk and the classification instability, which are proven to be the same rates as the oracle nearest neighbor classifier and cannot be improved. To significantly reduce the prediction time that is required for achieving the optimal rate, we also consider the pre-training acceleration technique applied to the bigNN method, with proven convergence rate. We find that in the distributed setting, the optimal choice of the neighbor k should scale with both the total sample size and the number of partitions, and there is a theoretical upper limit for the latter. Numerical studies have verified the theoretical findings.
Towards Run Time Estimation of the Gaussian Chemistry Code for SEAGrid Science Gateway
Jun 07, 2019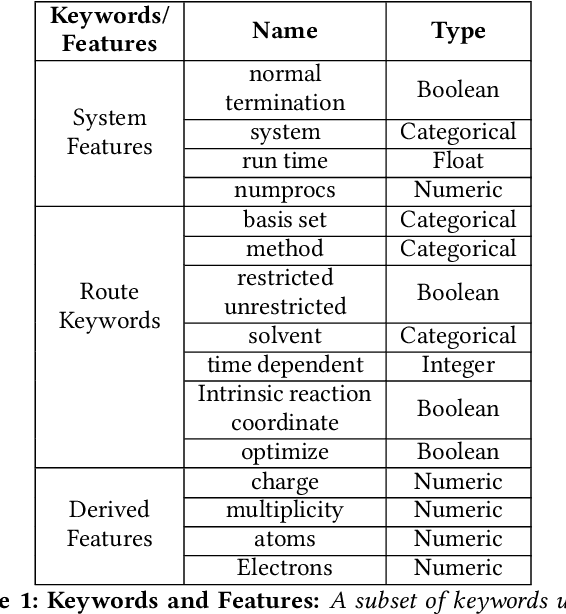
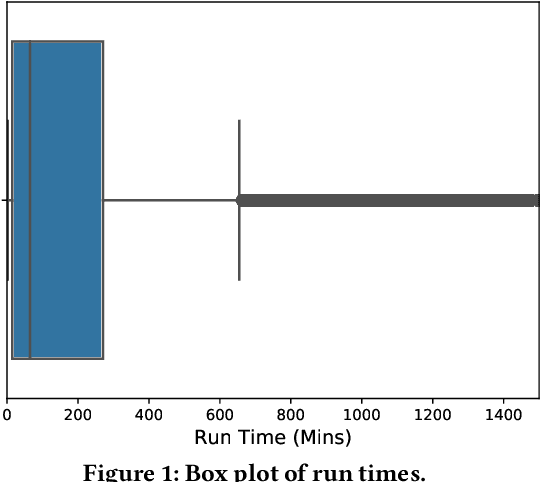
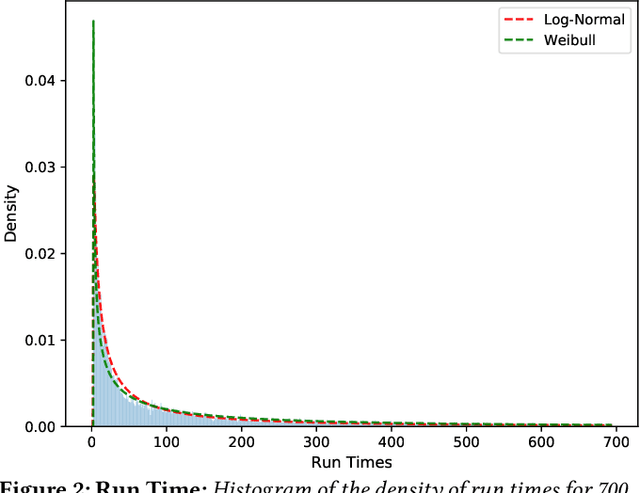

Accurate estimation of the run time of computational codes has a number of significant advantages for scientific computing. It is required information for optimal resource allocation, improving turnaround times and utilization of science gateways. Furthermore, it allows users to better plan and schedule their research, streamlining workflows and improving the overall productivity of cyberinfrastructure. Predicting run time is challenging, however. The inputs to scientific codes can be complex and high dimensional. Their relationship to the run time may be highly non-linear, and, in the most general case is completely arbitrary and thus unpredictable (i.e., simply a random mapping from inputs to run time). Most codes are not so arbitrary, however, and there has been significant prior research on predicting the run time of applications and workloads. Such predictions are generally application-specific, however. In this paper, we focus on the Gaussian computational chemistry code. We characterize a data set of runs from the SEAGrid science gateway with a number of different studies. We also explore a number of different potential regression methods and present promising future directions.