 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRates of Convergence for Large-scale Nearest Neighbor Classification
Paper and Code
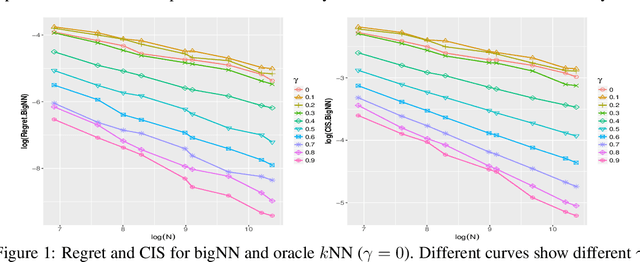
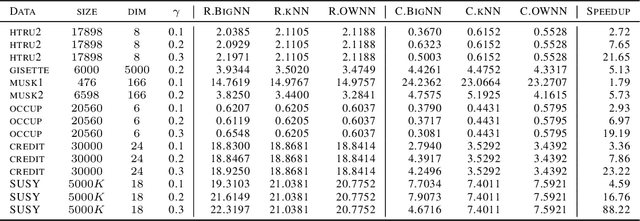
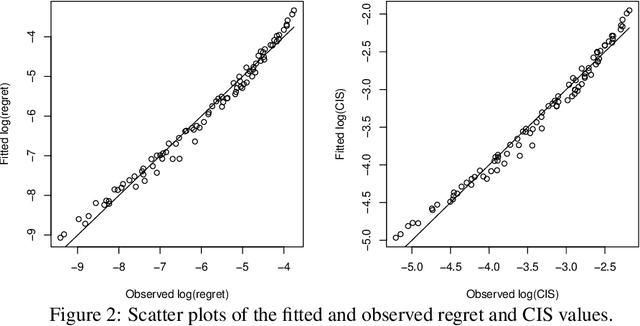
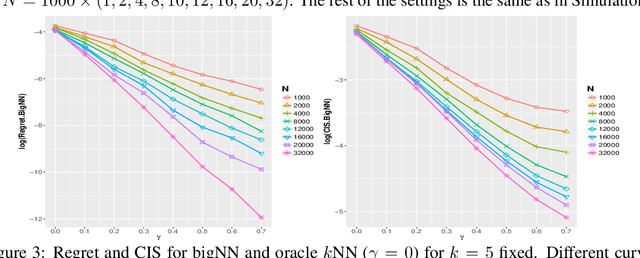
Nearest neighbor is a popular class of classification methods with many desirable properties. For a large data set which cannot be loaded into the memory of a single machine due to computation, communication, privacy, or ownership limitations, we consider the divide and conquer scheme: the entire data set is divided into small subsamples, on which nearest neighbor predictions are made, and then a final decision is reached by aggregating the predictions on subsamples by majority voting. We name this method the big Nearest Neighbor (bigNN) classifier, and provide its rates of convergence under minimal assumptions, in terms of both the excess risk and the classification instability, which are proven to be the same rates as the oracle nearest neighbor classifier and cannot be improved. To significantly reduce the prediction time that is required for achieving the optimal rate, we also consider the pre-training acceleration technique applied to the bigNN method, with proven convergence rate. We find that in the distributed setting, the optimal choice of the neighbor k should scale with both the total sample size and the number of partitions, and there is a theoretical upper limit for the latter. Numerical studies have verified the theoretical findings.