 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Entropy Diverse Exploration: Disentangling Maximum Entropy Reinforcement Learning
Paper and Code
Nov 03, 2019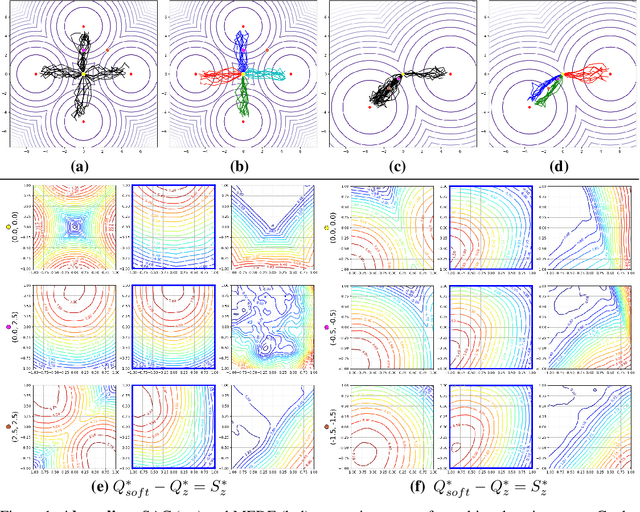
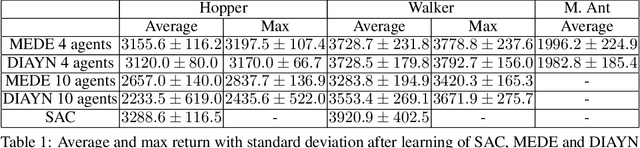
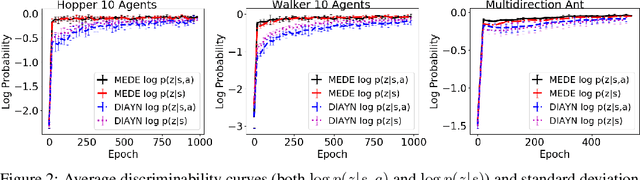
Two hitherto disconnected threads of research, diverse exploration (DE) and maximum entropy RL have addressed a wide range of problems facing reinforcement learning algorithms via ostensibly distinct mechanisms. In this work, we identify a connection between these two approaches. First, a discriminator-based diversity objective is put forward and connected to commonly used divergence measures. We then extend this objective to the maximum entropy framework and propose an algorithm Maximum Entropy Diverse Exploration (MEDE) which provides a principled method to learn diverse behaviors. A theoretical investigation shows that the set of policies learned by MEDE capture the same modalities as the optimal maximum entropy policy. In effect, the proposed algorithm disentangles the maximum entropy policy into its diverse, constituent policies. Experiments show that MEDE is superior to the state of the art in learning high performing and diverse policies.