 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSS-Net: Weakly-Supervised Multi-Class Semantic Segmentation with FMCW Radar
Paper and Code
Apr 02, 2020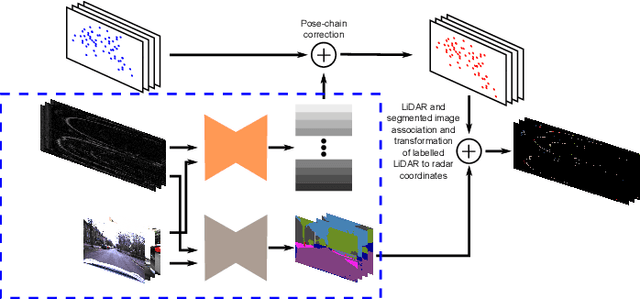
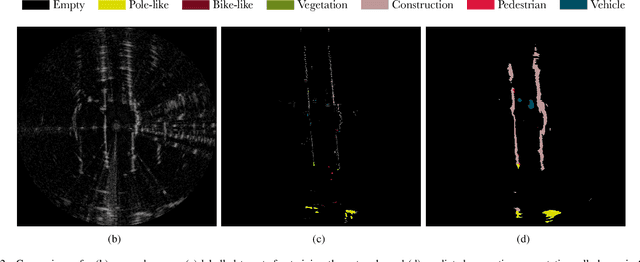


This paper presents an efficient annotation procedure and an application thereof to end-to-end, rich semantic segmentation of the sensed environment using FMCW scanning radar. We advocate radar over the traditional sensors used for this task as it operates at longer ranges and is substantially more robust to adverse weather and illumination conditions. We avoid laborious manual labelling by exploiting the largest radar-focused urban autonomy dataset collected to date, correlating radar scans with RGB cameras and LiDAR sensors, for which semantic segmentation is an already consolidated procedure. The training procedure leverages a state-of-the-art natural image segmentation system which is publicly available and as such, in contrast to previous approaches, allows for the production of copious labels for the radar stream by incorporating four camera and two LiDAR streams. Additionally, the losses are computed taking into account labels to the radar sensor horizon by accumulating LiDAR returns along a pose-chain ahead and behind of the current vehicle position. Finally, we present the network with multi-channel radar scan inputs in order to deal with ephemeral and dynamic scene objects.