 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Appearance Maps
Paper and Code
Apr 03, 2018
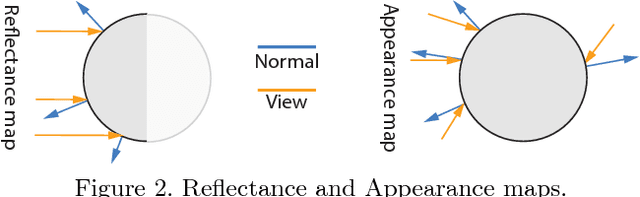

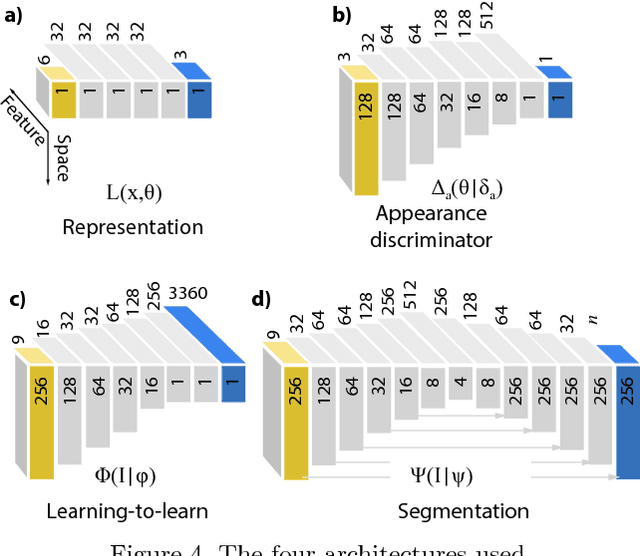
We propose a deep representation of appearance, i. e. the relation of color, surface orientation, viewer position, material and illumination. Previous approaches have used deep learning to extract classic appearance representations relating to reflectance model parameters (e. g. Phong) or illumination (e. g. HDR environment maps). We suggest to directly represent appearance itself as a network we call a deep appearance map (DAM). This is a 4D generalization over 2D reflectance maps, which held the view direction fixed. First, we show how a DAM can be learned from images or video frames and later be used to synthesize appearance, given new surface orientations and viewer positions. Second, we demonstrate how another network can be used to map from an image or video frames to a DAM network to reproduce this appearance, without using a lengthy optimization such as stochastic gradient descent (learning-to-learn). Finally, we generalize this to an appearance estimation-and-segmentation task, where we map from an image showing multiple materials to multiple networks reproducing their appearance, as well as per-pixel segmentation.