 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Harmonisation for Information Fusion in Digital Healthcare: A State-of-the-Art Systematic Review, Meta-Analysis and Future Research Directions
Jan 17, 2022

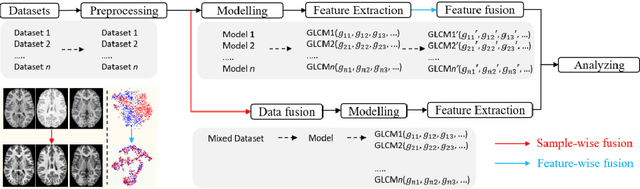
Removing the bias and variance of multicentre data has always been a challenge in large scale digital healthcare studies, which requires the ability to integrate clinical features extracted from data acquired by different scanners and protocols to improve stability and robustness. Previous studies have described various computational approaches to fuse single modality multicentre datasets. However, these surveys rarely focused on evaluation metrics and lacked a checklist for computational data harmonisation studies. In this systematic review, we summarise the computational data harmonisation approaches for multi-modality data in the digital healthcare field, including harmonisation strategies and evaluation metrics based on different theories. In addition, a comprehensive checklist that summarises common practices for data harmonisation studies is proposed to guide researchers to report their research findings more effectively. Last but not least, flowcharts presenting possible ways for methodology and metric selection are proposed and the limitations of different methods have been surveyed for future research.
Transparency of Deep Neural Networks for Medical Image Analysis: A Review of Interpretability Methods
Nov 01, 2021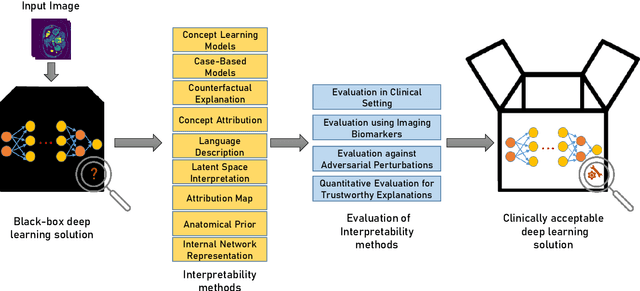
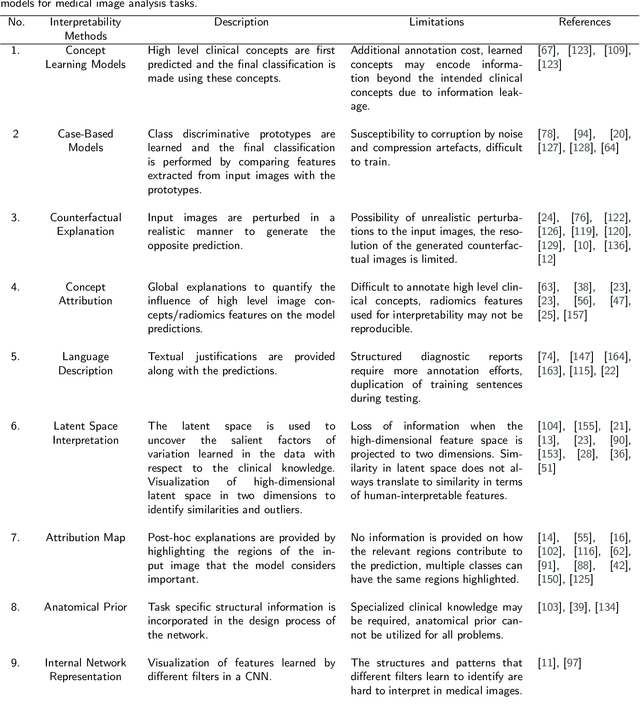
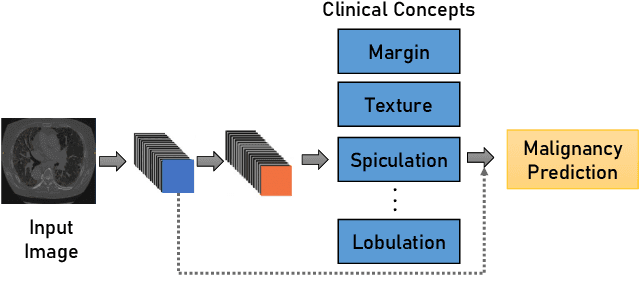
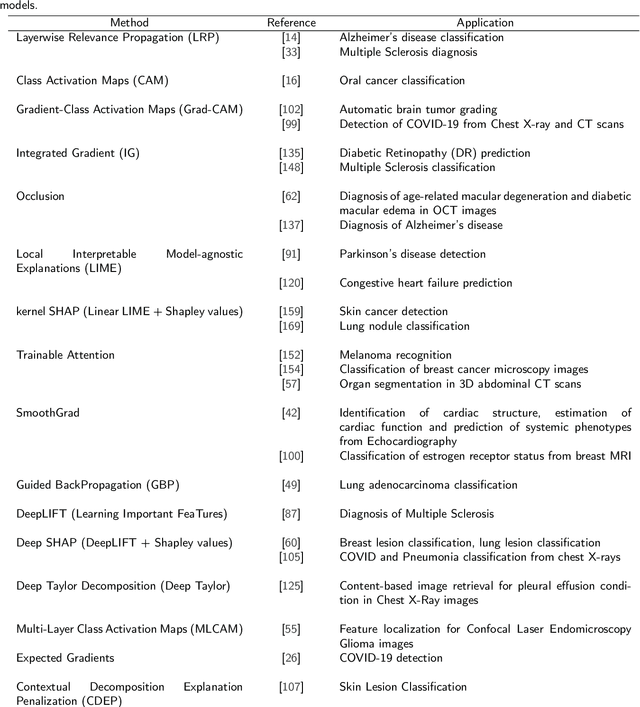
Artificial Intelligence has emerged as a useful aid in numerous clinical applications for diagnosis and treatment decisions. Deep neural networks have shown same or better performance than clinicians in many tasks owing to the rapid increase in the available data and computational power. In order to conform to the principles of trustworthy AI, it is essential that the AI system be transparent, robust, fair and ensure accountability. Current deep neural solutions are referred to as black-boxes due to a lack of understanding of the specifics concerning the decision making process. Therefore, there is a need to ensure interpretability of deep neural networks before they can be incorporated in the routine clinical workflow. In this narrative review, we utilized systematic keyword searches and domain expertise to identify nine different types of interpretability methods that have been used for understanding deep learning models for medical image analysis applications based on the type of generated explanations and technical similarities. Furthermore, we report the progress made towards evaluating the explanations produced by various interpretability methods. Finally we discuss limitations, provide guidelines for using interpretability methods and future directions concerning the interpretability of deep neural networks for medical imaging analysis.
Functional Classwise Principal Component Analysis: A Novel Classification Framework
Jun 26, 2021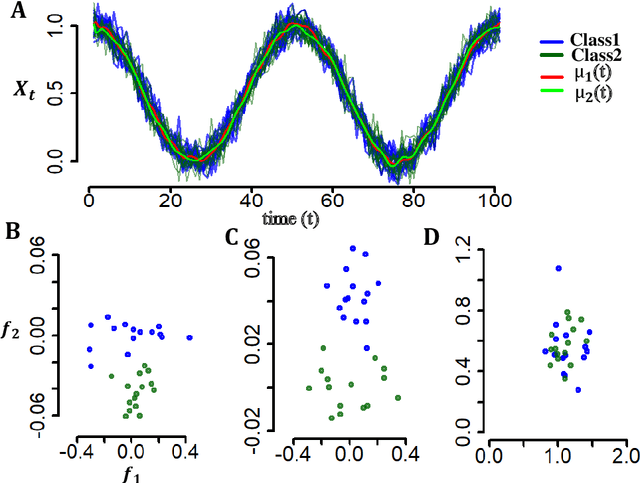
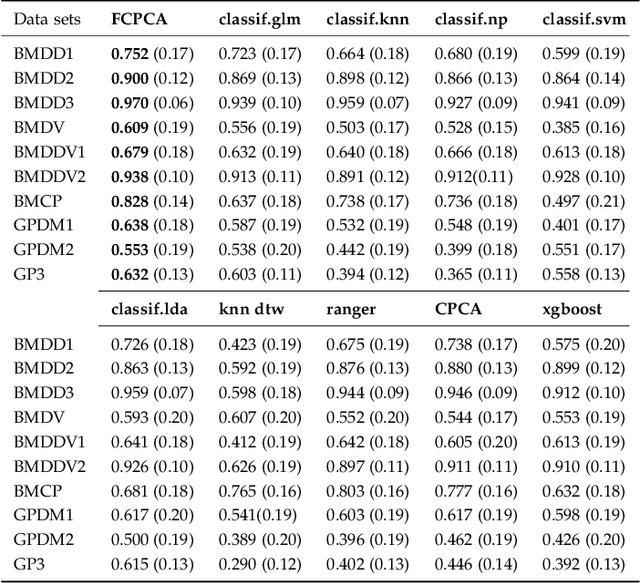
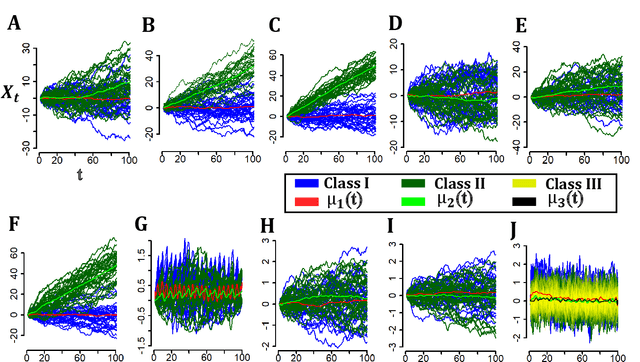
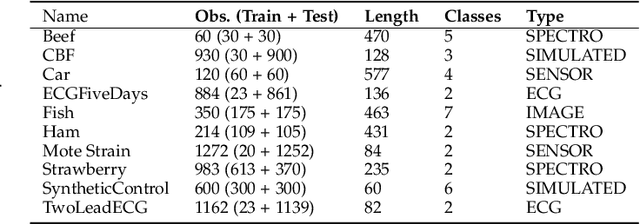
In recent times, functional data analysis (FDA) has been successfully applied in the field of high dimensional data classification. In this paper, we present a novel classification framework using functional data and classwise Principal Component Analysis (PCA). Our proposed method can be used in high dimensional time series data which typically suffers from small sample size problem. Our method extracts a piece wise linear functional feature space and is particularly suitable for hard classification problems.The proposed framework converts time series data into functional data and uses classwise functional PCA for feature extraction followed by classification using a Bayesian linear classifier. We demonstrate the efficacy of our proposed method by applying it to both synthetic data sets and real time series data from diverse fields including but not limited to neuroscience, food science, medical sciences and chemometrics.
LIME: Live Intrinsic Material Estimation
May 04, 2018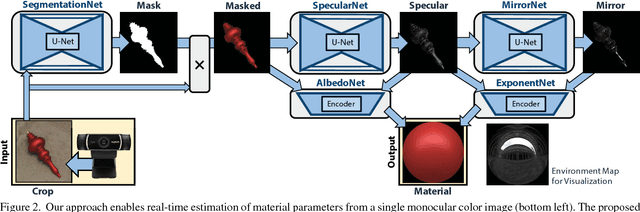
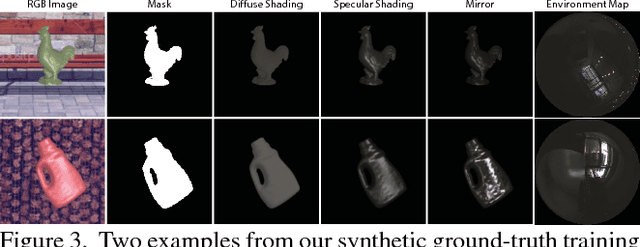


We present the first end to end approach for real time material estimation for general object shapes with uniform material that only requires a single color image as input. In addition to Lambertian surface properties, our approach fully automatically computes the specular albedo, material shininess, and a foreground segmentation. We tackle this challenging and ill posed inverse rendering problem using recent advances in image to image translation techniques based on deep convolutional encoder decoder architectures. The underlying core representations of our approach are specular shading, diffuse shading and mirror images, which allow to learn the effective and accurate separation of diffuse and specular albedo. In addition, we propose a novel highly efficient perceptual rendering loss that mimics real world image formation and obtains intermediate results even during run time. The estimation of material parameters at real time frame rates enables exciting mixed reality applications, such as seamless illumination consistent integration of virtual objects into real world scenes, and virtual material cloning. We demonstrate our approach in a live setup, compare it to the state of the art, and demonstrate its effectiveness through quantitative and qualitative evaluation.
Mo2Cap2: Real-time Mobile 3D Motion Capture with a Cap-mounted Fisheye Camera
Mar 15, 2018



We propose the first real-time approach for the egocentric estimation of 3D human body pose in a wide range of unconstrained everyday activities. This setting has a unique set of challenges, such as mobility of the hardware setup, and robustness to long capture sessions with fast recovery from tracking failures. We tackle these challenges based on a novel lightweight setup that converts a standard baseball cap to a device for high-quality pose estimation based on a single cap-mounted fisheye camera. From the captured egocentric live stream, our CNN based 3D pose estimation approach runs at 60Hz on a consumer-level GPU. In addition to the novel hardware setup, our other main contributions are: 1) a large ground truth training corpus of top-down fisheye images and 2) a novel disentangled 3D pose estimation approach that takes the unique properties of the egocentric viewpoint into account. As shown by our evaluation, we achieve lower 3D joint error as well as better 2D overlay than the existing baselines.
MonoPerfCap: Human Performance Capture from Monocular Video
Feb 23, 2018

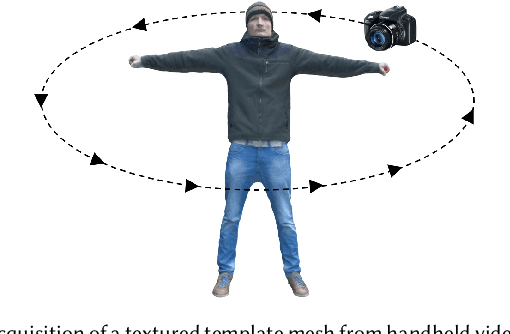
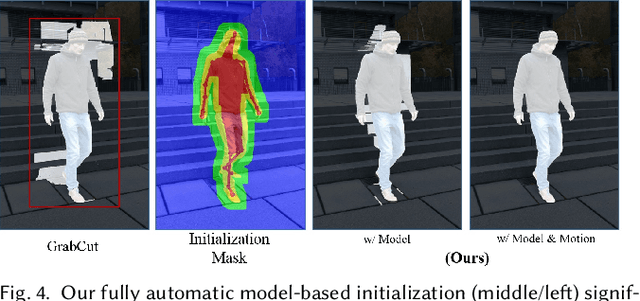
We present the first marker-less approach for temporally coherent 3D performance capture of a human with general clothing from monocular video. Our approach reconstructs articulated human skeleton motion as well as medium-scale non-rigid surface deformations in general scenes. Human performance capture is a challenging problem due to the large range of articulation, potentially fast motion, and considerable non-rigid deformations, even from multi-view data. Reconstruction from monocular video alone is drastically more challenging, since strong occlusions and the inherent depth ambiguity lead to a highly ill-posed reconstruction problem. We tackle these challenges by a novel approach that employs sparse 2D and 3D human pose detections from a convolutional neural network using a batch-based pose estimation strategy. Joint recovery of per-batch motion allows to resolve the ambiguities of the monocular reconstruction problem based on a low dimensional trajectory subspace. In addition, we propose refinement of the surface geometry based on fully automatically extracted silhouettes to enable medium-scale non-rigid alignment. We demonstrate state-of-the-art performance capture results that enable exciting applications such as video editing and free viewpoint video, previously infeasible from monocular video. Our qualitative and quantitative evaluation demonstrates that our approach significantly outperforms previous monocular methods in terms of accuracy, robustness and scene complexity that can be handled.
Noise in Structured-Light Stereo Depth Cameras: Modeling and its Applications
May 08, 2015
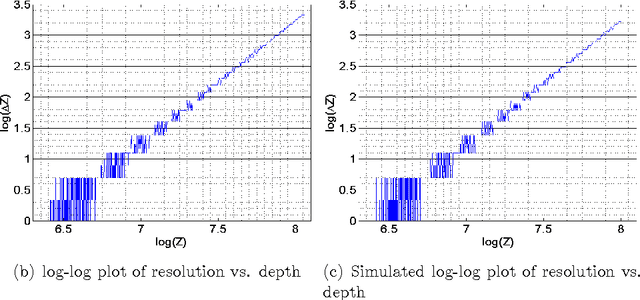


Depth maps obtained from commercially available structured-light stereo based depth cameras, such as the Kinect, are easy to use but are affected by significant amounts of noise. This paper is devoted to a study of the intrinsic noise characteristics of such depth maps, i.e. the standard deviation of noise in estimated depth varies quadratically with the distance of the object from the depth camera. We validate this theoretical model against empirical observations and demonstrate the utility of this noise model in three popular applications: depth map denoising, volumetric scan merging for 3D modeling, and identification of 3D planes in depth maps.