 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactuals and Uncertainty-Based Explainable Paradigm for the Automated Detection and Segmentation of Renal Cysts in Computed Tomography Images: A Multi-Center Study
Aug 07, 2024Routine computed tomography (CT) scans often detect a wide range of renal cysts, some of which may be malignant. Early and precise localization of these cysts can significantly aid quantitative image analysis. Current segmentation methods, however, do not offer sufficient interpretability at the feature and pixel levels, emphasizing the necessity for an explainable framework that can detect and rectify model inaccuracies. We developed an interpretable segmentation framework and validated it on a multi-centric dataset. A Variational Autoencoder Generative Adversarial Network (VAE-GAN) was employed to learn the latent representation of 3D input patches and reconstruct input images. Modifications in the latent representation using the gradient of the segmentation model generated counterfactual explanations for varying dice similarity coefficients (DSC). Radiomics features extracted from these counterfactual images, using a ground truth cyst mask, were analyzed to determine their correlation with segmentation performance. The DSCs for the original and VAE-GAN reconstructed images for counterfactual image generation showed no significant differences. Counterfactual explanations highlighted how variations in cyst image features influence segmentation outcomes and showed model discrepancies. Radiomics features correlating positively and negatively with dice scores were identified. The uncertainty of the predicted segmentation masks was estimated using posterior sampling of the weight space. The combination of counterfactual explanations and uncertainty maps provided a deeper understanding of the image features within the segmented renal cysts that lead to high uncertainty. The proposed segmentation framework not only achieved high segmentation accuracy but also increased interpretability regarding how image features impact segmentation performance.
Methodological Explainability Evaluation of an Interpretable Deep Learning Model for Post-Hepatectomy Liver Failure Prediction Incorporating Counterfactual Explanations and Layerwise Relevance Propagation: A Prospective In Silico Trial
Aug 07, 2024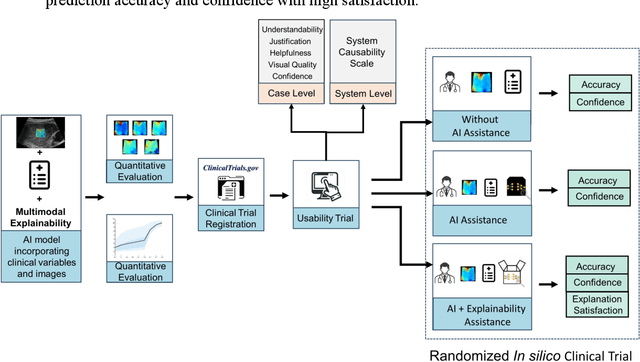
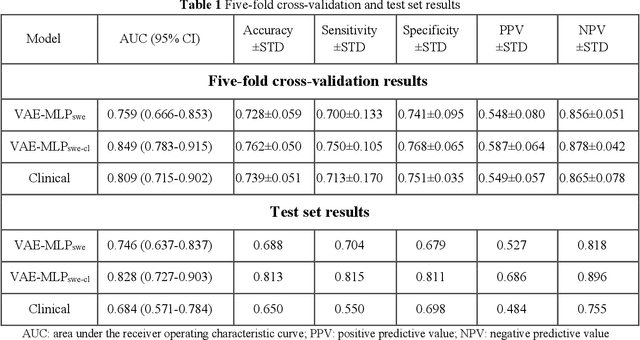
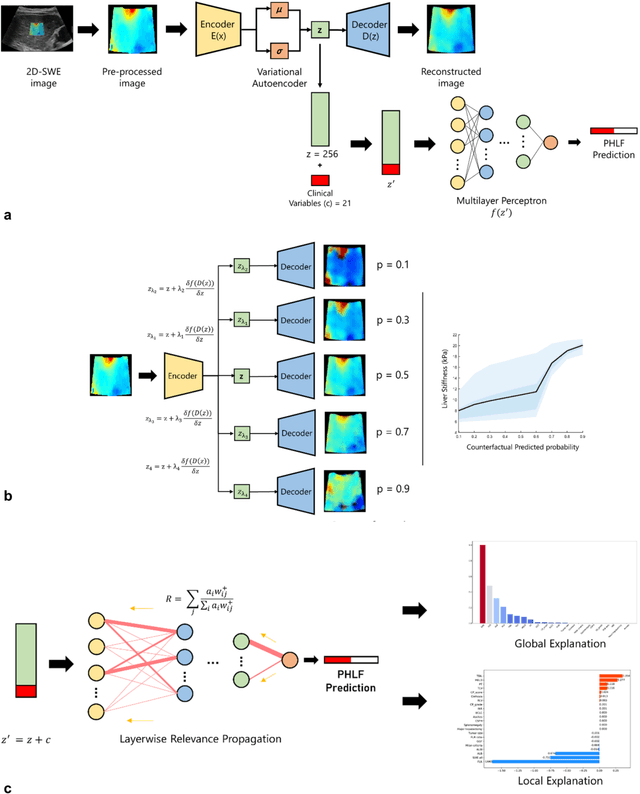
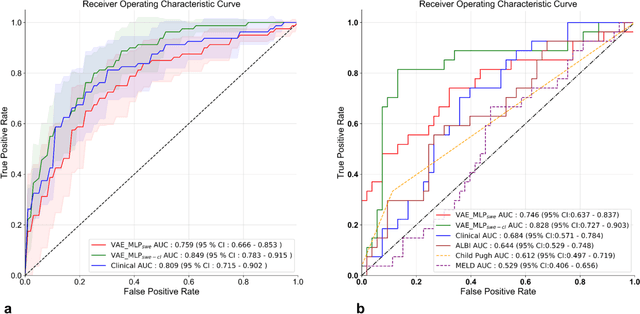
Artificial intelligence (AI)-based decision support systems have demonstrated value in predicting post-hepatectomy liver failure (PHLF) in hepatocellular carcinoma (HCC). However, they often lack transparency, and the impact of model explanations on clinicians' decisions has not been thoroughly evaluated. Building on prior research, we developed a variational autoencoder-multilayer perceptron (VAE-MLP) model for preoperative PHLF prediction. This model integrated counterfactuals and layerwise relevance propagation (LRP) to provide insights into its decision-making mechanism. Additionally, we proposed a methodological framework for evaluating the explainability of AI systems. This framework includes qualitative and quantitative assessments of explanations against recognized biomarkers, usability evaluations, and an in silico clinical trial. Our evaluations demonstrated that the model's explanation correlated with established biomarkers and exhibited high usability at both the case and system levels. Furthermore, results from the three-track in silico clinical trial showed that clinicians' prediction accuracy and confidence increased when AI explanations were provided.
Precision-medicine-toolbox: An open-source python package for facilitation of quantitative medical imaging and radiomics analysis
Feb 28, 2022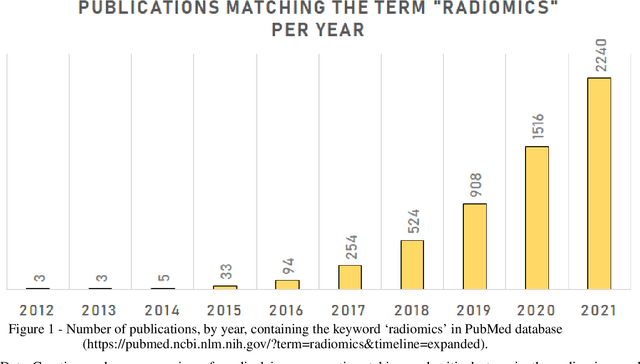
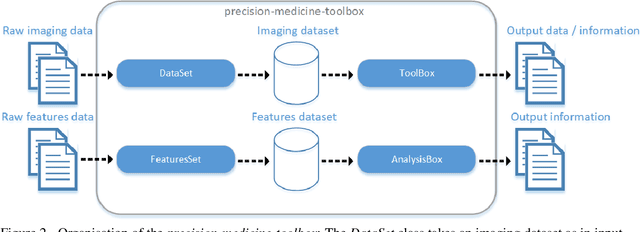
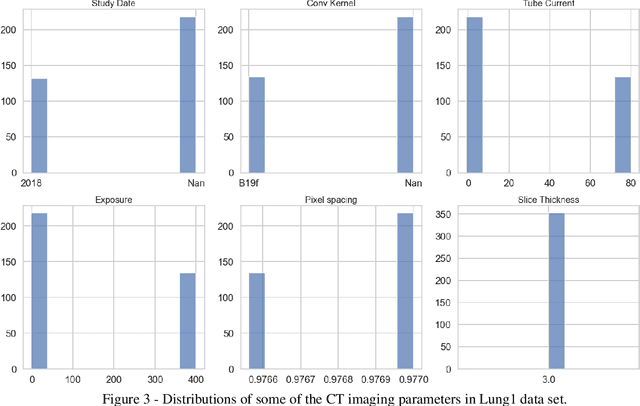
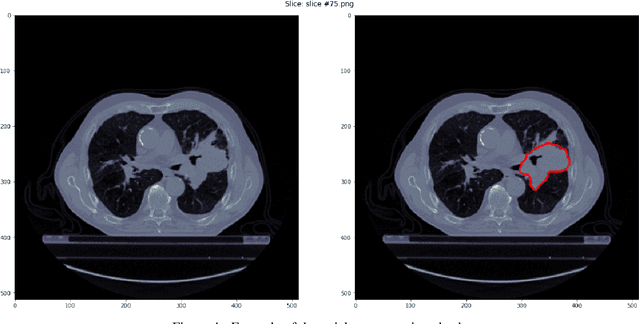
Medical image analysis plays a key role in precision medicine as it allows the clinicians to identify anatomical abnormalities and it is routinely used in clinical assessment. Data curation and pre-processing of medical images are critical steps in the quantitative medical image analysis that can have a significant impact on the resulting model performance. In this paper, we introduce a precision-medicine-toolbox that allows researchers to perform data curation, image pre-processing and handcrafted radiomics extraction (via Pyradiomics) and feature exploration tasks with Python. With this open-source solution, we aim to address the data preparation and exploration problem, bridge the gap between the currently existing packages, and improve the reproducibility of quantitative medical imaging research.
Transparency of Deep Neural Networks for Medical Image Analysis: A Review of Interpretability Methods
Nov 01, 2021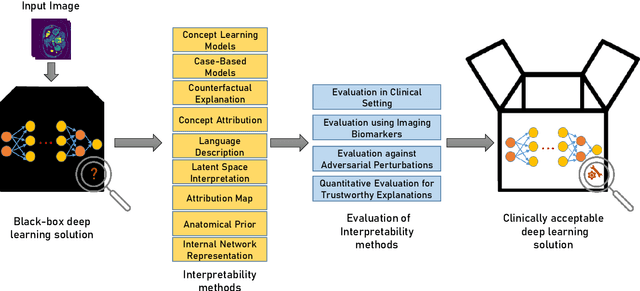
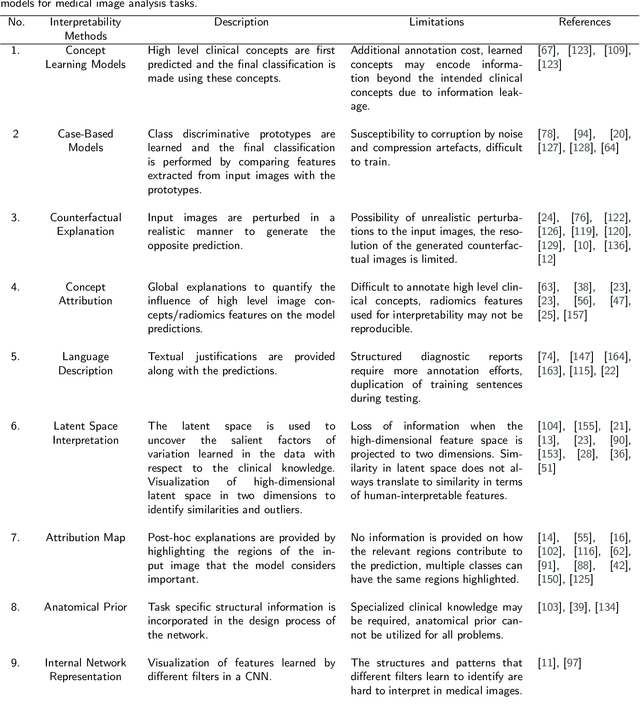
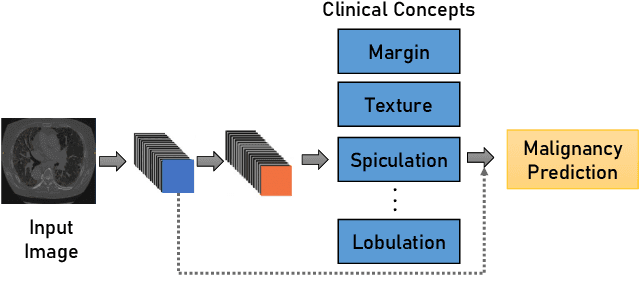
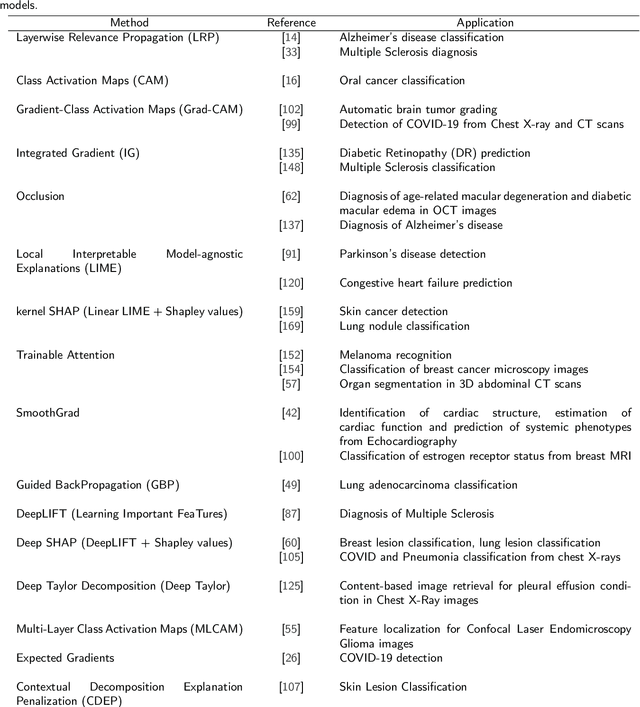
Artificial Intelligence has emerged as a useful aid in numerous clinical applications for diagnosis and treatment decisions. Deep neural networks have shown same or better performance than clinicians in many tasks owing to the rapid increase in the available data and computational power. In order to conform to the principles of trustworthy AI, it is essential that the AI system be transparent, robust, fair and ensure accountability. Current deep neural solutions are referred to as black-boxes due to a lack of understanding of the specifics concerning the decision making process. Therefore, there is a need to ensure interpretability of deep neural networks before they can be incorporated in the routine clinical workflow. In this narrative review, we utilized systematic keyword searches and domain expertise to identify nine different types of interpretability methods that have been used for understanding deep learning models for medical image analysis applications based on the type of generated explanations and technical similarities. Furthermore, we report the progress made towards evaluating the explanations produced by various interpretability methods. Finally we discuss limitations, provide guidelines for using interpretability methods and future directions concerning the interpretability of deep neural networks for medical imaging analysis.
FUTURE-AI: Guiding Principles and Consensus Recommendations for Trustworthy Artificial Intelligence in Medical Imaging
Sep 29, 2021
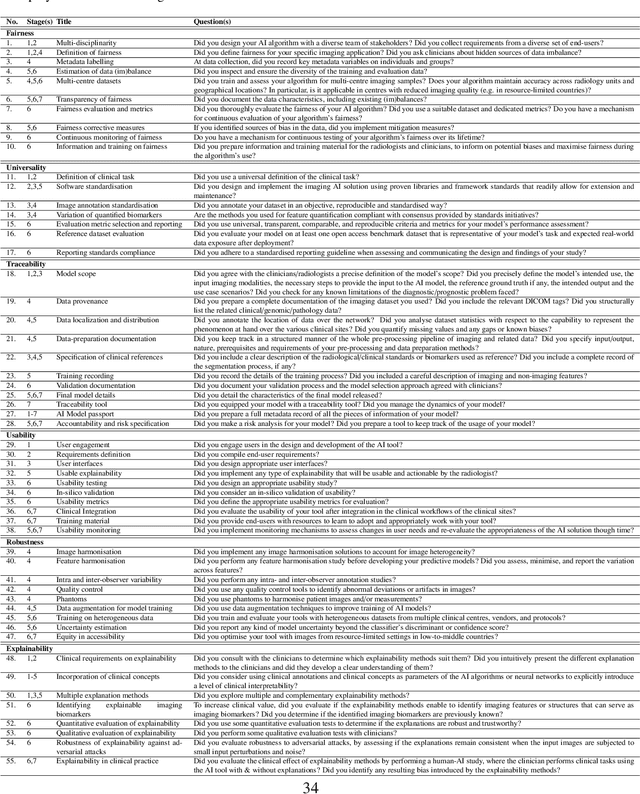
The recent advancements in artificial intelligence (AI) combined with the extensive amount of data generated by today's clinical systems, has led to the development of imaging AI solutions across the whole value chain of medical imaging, including image reconstruction, medical image segmentation, image-based diagnosis and treatment planning. Notwithstanding the successes and future potential of AI in medical imaging, many stakeholders are concerned of the potential risks and ethical implications of imaging AI solutions, which are perceived as complex, opaque, and difficult to comprehend, utilise, and trust in critical clinical applications. Despite these concerns and risks, there are currently no concrete guidelines and best practices for guiding future AI developments in medical imaging towards increased trust, safety and adoption. To bridge this gap, this paper introduces a careful selection of guiding principles drawn from the accumulated experiences, consensus, and best practices from five large European projects on AI in Health Imaging. These guiding principles are named FUTURE-AI and its building blocks consist of (i) Fairness, (ii) Universality, (iii) Traceability, (iv) Usability, (v) Robustness and (vi) Explainability. In a step-by-step approach, these guidelines are further translated into a framework of concrete recommendations for specifying, developing, evaluating, and deploying technically, clinically and ethically trustworthy AI solutions into clinical practice.