 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of White-box Deployment Strategies for Edge AI on Latency and Model Performance
Paper and Code

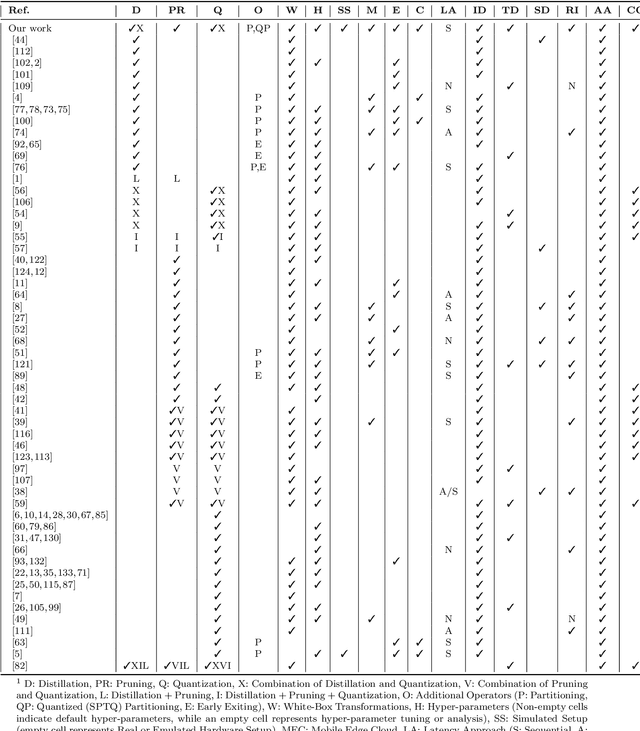

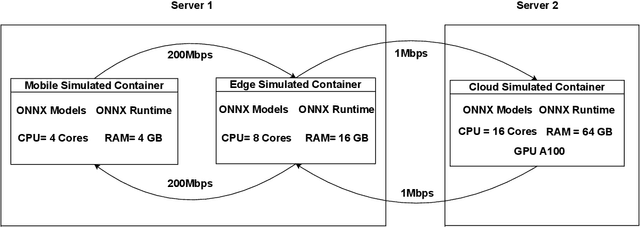
To help MLOps engineers decide which operator to use in which deployment scenario, this study aims to empirically assess the accuracy vs latency trade-off of white-box (training-based) and black-box operators (non-training-based) and their combinations in an Edge AI setup. We perform inference experiments including 3 white-box (i.e., QAT, Pruning, Knowledge Distillation), 2 black-box (i.e., Partition, SPTQ), and their combined operators (i.e., Distilled SPTQ, SPTQ Partition) across 3 tiers (i.e., Mobile, Edge, Cloud) on 4 commonly-used Computer Vision and Natural Language Processing models to identify the effective strategies, considering the perspective of MLOps Engineers. Our Results indicate that the combination of Distillation and SPTQ operators (i.e., DSPTQ) should be preferred over non-hybrid operators when lower latency is required in the edge at small to medium accuracy drop. Among the non-hybrid operators, the Distilled operator is a better alternative in both mobile and edge tiers for lower latency performance at the cost of small to medium accuracy loss. Moreover, the operators involving distillation show lower latency in resource-constrained tiers (Mobile, Edge) compared to the operators involving Partitioning across Mobile and Edge tiers. For textual subject models, which have low input data size requirements, the Cloud tier is a better alternative for the deployment of operators than the Mobile, Edge, or Mobile-Edge tier (the latter being used for operators involving partitioning). In contrast, for image-based subject models, which have high input data size requirements, the Edge tier is a better alternative for operators than Mobile, Edge, or their combination.