 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackpropagation-Free 4D Continuous Ant-Based Neural Topology Search
May 11, 2023



Continuous Ant-based Topology Search (CANTS) is a previously introduced novel nature-inspired neural architecture search (NAS) algorithm that is based on ant colony optimization (ACO). CANTS utilizes a continuous search space to indirectly-encode a neural architecture search space. Synthetic ant agents explore CANTS' continuous search space based on the density and distribution of pheromones, strongly inspired by how ants move in the real world. This continuous search space allows CANTS to automate the design of artificial neural networks (ANNs) of any size, removing a key limitation inherent to many current NAS algorithms that must operate within structures of a size that is predetermined by the user. This work expands CANTS by adding a fourth dimension to its search space representing potential neural synaptic weights. Adding this extra dimension allows CANTS agents to optimize both the architecture as well as the weights of an ANN without applying backpropagation (BP), which leads to a significant reduction in the time consumed in the optimization process. The experiments of this study - using real-world data - demonstrate that the BP-Free~CANTS algorithm exhibits highly competitive performance compared to both CANTS and ANTS while requiring significantly less operation time.
An Examination of Bias of Facial Analysis based BMI Prediction Models
Apr 21, 2022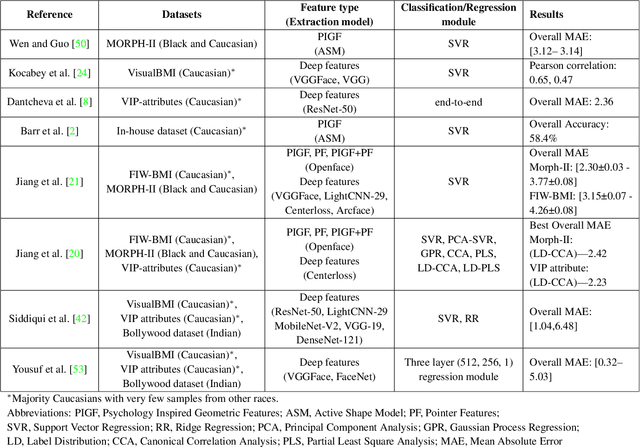


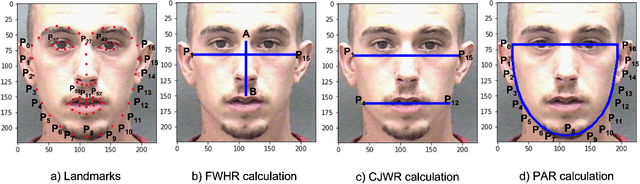
Obesity is one of the most important public health problems that the world is facing today. A recent trend is in the development of intervention tools that predict BMI using facial images for weight monitoring and management to combat obesity. Most of these studies used BMI annotated facial image datasets that mainly consisted of Caucasian subjects. Research on bias evaluation of face-based gender-, age-classification, and face recognition systems suggest that these technologies perform poorly for women, dark-skinned people, and older adults. The bias of facial analysis-based BMI prediction tools has not been studied until now. This paper evaluates the bias of facial-analysis-based BMI prediction models across Caucasian and African-American Males and Females. Experimental investigations on the gender, race, and BMI balanced version of the modified MORPH-II dataset suggested that the error rate in BMI prediction was least for Black Males and highest for White Females. Further, the psychology-related facial features correlated with weight suggested that as the BMI increases, the changes in the facial region are more prominent for Black Males and the least for White Females. This is the reason for the least error rate of the facial analysis-based BMI prediction tool for Black Males and highest for White Females.
Identity Document to Selfie Face Matching Across Adolescence
Dec 20, 2019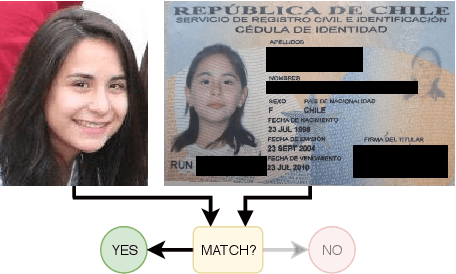
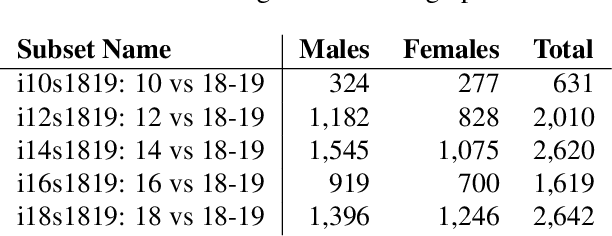
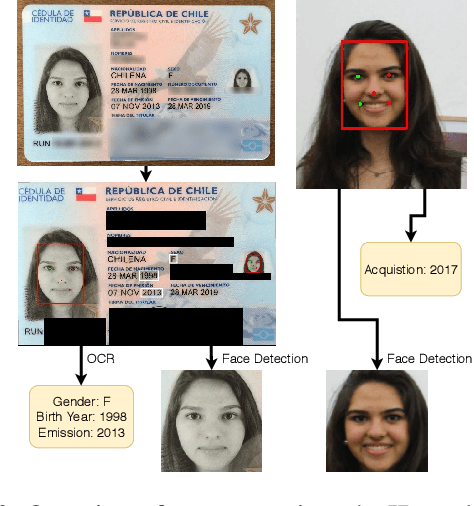
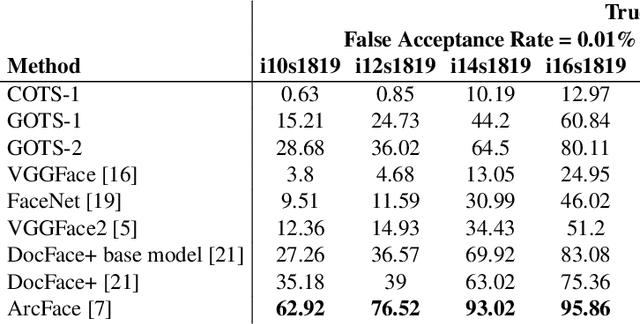
Matching live images (``selfies'') to images from ID documents is a problem that can arise in various applications. A challenging instance of the problem arises when the face image on the ID document is from early adolescence and the live image is from later adolescence. We explore this problem using a private dataset called Chilean Young Adult (CHIYA) dataset, where we match live face images taken at age 18-19 to face images on ID documents created at ages 9 to 18. State-of-the-art deep learning face matchers (e.g., ArcFace) have relatively poor accuracy for document-to-selfie face matching. To achieve higher accuracy, we fine-tune the best available open-source model with triplet loss for a few-shot learning. Experiments show that our approach achieves higher accuracy than the DocFace+ model recently developed for this problem. Our fine-tuned model was able to improve the true acceptance rate for the most difficult (largest age span) subset from 62.92% to 96.67% at a false acceptance rate of 0.01%. Our fine-tuned model is available for use by other researchers.
Non-Volume Preserving-based Feature Fusion Approach to Group-Level Expression Recognition on Crowd Videos
Nov 28, 2018
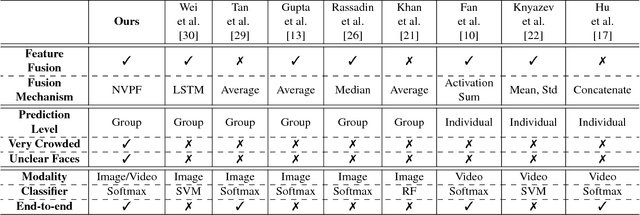

Group-level emotion recognition (ER) is a growing research area as the demands for assessing crowds of all sizes is becoming an interest in both the security arena and social media. This work investigates group-level expression recognition on crowd videos where information is not only aggregated across a variable length sequence of frames but also over the set of faces within each frame to produce aggregated recognition results. In this paper, we propose an effective deep feature level fusion mechanism to model the spatial-temporal information in the crowd videos. Furthermore, we extend our proposed NVP fusion mechanism to temporal NVP fussion appoarch to learn the temporal information between frames. In order to demonstrate the robustness and effectiveness of each component in the proposed approach, three experiments were conducted: (i) evaluation on the AffectNet database to benchmark the proposed emoNet for recognizing facial expression; (ii) evaluation on EmotiW2018 to benchmark the proposed deep feature level fusion mechanism NVPF; and, (iii) examine the proposed TNVPF on an innovative Group-level Emotion on Crowd Videos (GECV) dataset composed of 627 videos collected from social media. GECV dataset is a collection of videos ranging in duration from 10 to 20 seconds of crowds of twenty (20) or more subjects and each video is labeled as positive, negative, or neutral.