 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comunication Framework for Compositional Generation
Jan 31, 2025Compositionality and compositional generalization--the ability to understand novel combinations of known concepts--are central characteristics of human language and are hypothesized to be essential for human cognition. In machine learning, the emergence of this property has been studied in a communication game setting, where independent agents (a sender and a receiver) converge to a shared encoding policy from a set of states to a space of discrete messages, where the receiver can correctly reconstruct the states observed by the sender using only the sender's messages. The use of communication games in generation tasks is still largely unexplored, with recent methods for compositional generation focusing mainly on the use of supervised guidance (either through class labels or text). In this work, we take the first steps to fill this gap, and we present a self-supervised generative communication game-based framework for creating compositional encodings in learned representations from pre-trained encoder-decoder models. In an Iterated Learning (IL) protocol involving a sender and a receiver, we apply alternating pressures for compression and diversity of encoded discrete messages, so that the protocol converges to an efficient but unambiguous encoding. Approximate message entropy regularization is used to favor compositional encodings. Our framework is based on rigorous justifications and proofs of defining and balancing the concepts of Eficiency, Unambiguity and Non-Holisticity in encoding. We test our method on the compositional image dataset Shapes3D, demonstrating robust performance in both reconstruction and compositionality metrics, surpassing other tested discrete message frameworks.
Long Tail Image Generation Through Feature Space Augmentation and Iterated Learning
May 02, 2024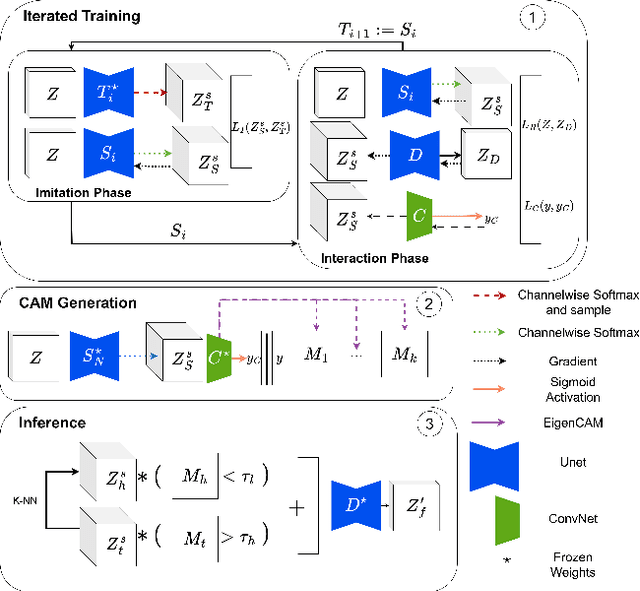
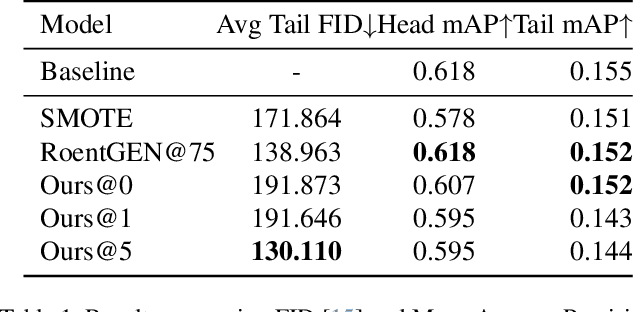
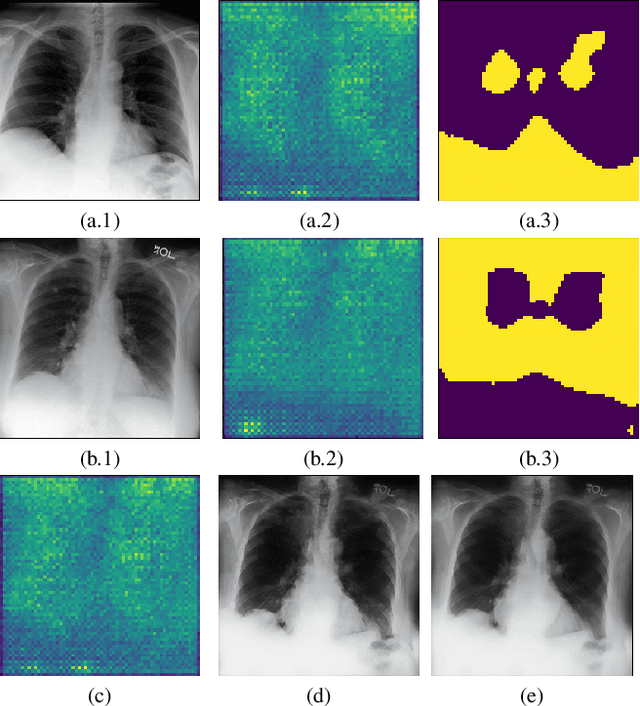
Image and multimodal machine learning tasks are very challenging to solve in the case of poorly distributed data. In particular, data availability and privacy restrictions exacerbate these hurdles in the medical domain. The state of the art in image generation quality is held by Latent Diffusion models, making them prime candidates for tackling this problem. However, a few key issues still need to be solved, such as the difficulty in generating data from under-represented classes and a slow inference process. To mitigate these issues, we propose a new method for image augmentation in long-tailed data based on leveraging the rich latent space of pre-trained Stable Diffusion Models. We create a modified separable latent space to mix head and tail class examples. We build this space via Iterated Learning of underlying sparsified embeddings, which we apply to task-specific saliency maps via a K-NN approach. Code is available at https://github.com/SugarFreeManatee/Feature-Space-Augmentation-and-Iterated-Learning