 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Neural Rendering Methods with Image Augmentations
Paper and Code
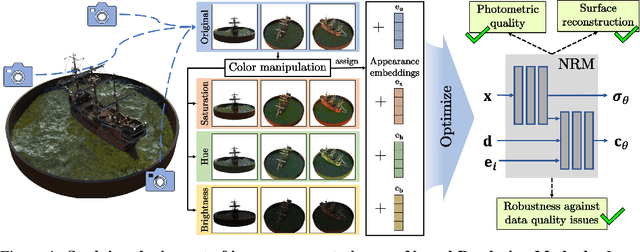
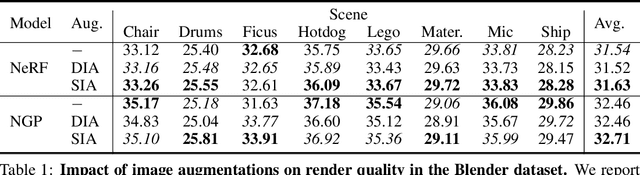


Faithfully reconstructing 3D geometry and generating novel views of scenes are critical tasks in 3D computer vision. Despite the widespread use of image augmentations across computer vision applications, their potential remains underexplored when learning neural rendering methods (NRMs) for 3D scenes. This paper presents a comprehensive analysis of the use of image augmentations in NRMs, where we explore different augmentation strategies. We found that introducing image augmentations during training presents challenges such as geometric and photometric inconsistencies for learning NRMs from images. Specifically, geometric inconsistencies arise from alterations in shapes, positions, and orientations from the augmentations, disrupting spatial cues necessary for accurate 3D reconstruction. On the other hand, photometric inconsistencies arise from changes in pixel intensities introduced by the augmentations, affecting the ability to capture the underlying 3D structures of the scene. We alleviate these issues by focusing on color manipulations and introducing learnable appearance embeddings that allow NRMs to explain away photometric variations. Our experiments demonstrate the benefits of incorporating augmentations when learning NRMs, including improved photometric quality and surface reconstruction, as well as enhanced robustness against data quality issues, such as reduced training data and image degradations.