 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinner: Shining Light on Digital Twins in a Few Snaps
Paper and Code
Mar 11, 2025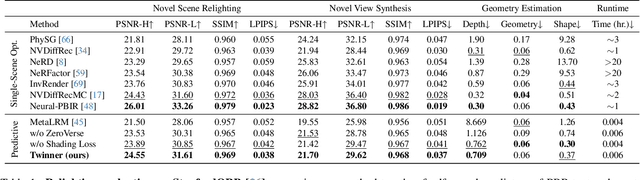
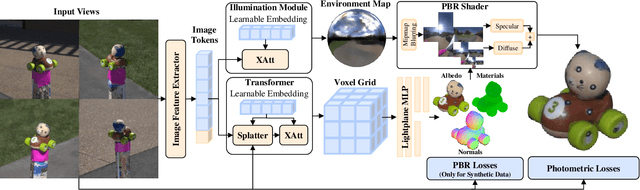
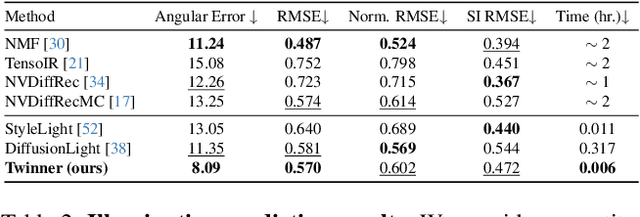
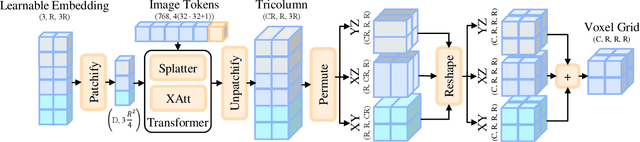
We present the first large reconstruction model, Twinner, capable of recovering a scene's illumination as well as an object's geometry and material properties from only a few posed images. Twinner is based on the Large Reconstruction Model and innovates in three key ways: 1) We introduce a memory-efficient voxel-grid transformer whose memory scales only quadratically with the size of the voxel grid. 2) To deal with scarcity of high-quality ground-truth PBR-shaded models, we introduce a large fully-synthetic dataset of procedurally-generated PBR-textured objects lit with varied illumination. 3) To narrow the synthetic-to-real gap, we finetune the model on real life datasets by means of a differentiable physically-based shading model, eschewing the need for ground-truth illumination or material properties which are challenging to obtain in real life. We demonstrate the efficacy of our model on the real life StanfordORB benchmark where, given few input views, we achieve reconstruction quality significantly superior to existing feedforward reconstruction networks, and comparable to significantly slower per-scene optimization methods.