 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
Jan 26, 2026The rise of AI agents introduces complex safety and security challenges arising from autonomous tool use and environmental interactions. Current guardrail models lack agentic risk awareness and transparency in risk diagnosis. To introduce an agentic guardrail that covers complex and numerous risky behaviors, we first propose a unified three-dimensional taxonomy that orthogonally categorizes agentic risks by their source (where), failure mode (how), and consequence (what). Guided by this structured and hierarchical taxonomy, we introduce a new fine-grained agentic safety benchmark (ATBench) and a Diagnostic Guardrail framework for agent safety and security (AgentDoG). AgentDoG provides fine-grained and contextual monitoring across agent trajectories. More Crucially, AgentDoG can diagnose the root causes of unsafe actions and seemingly safe but unreasonable actions, offering provenance and transparency beyond binary labels to facilitate effective agent alignment. AgentDoG variants are available in three sizes (4B, 7B, and 8B parameters) across Qwen and Llama model families. Extensive experimental results demonstrate that AgentDoG achieves state-of-the-art performance in agentic safety moderation in diverse and complex interactive scenarios. All models and datasets are openly released.
Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025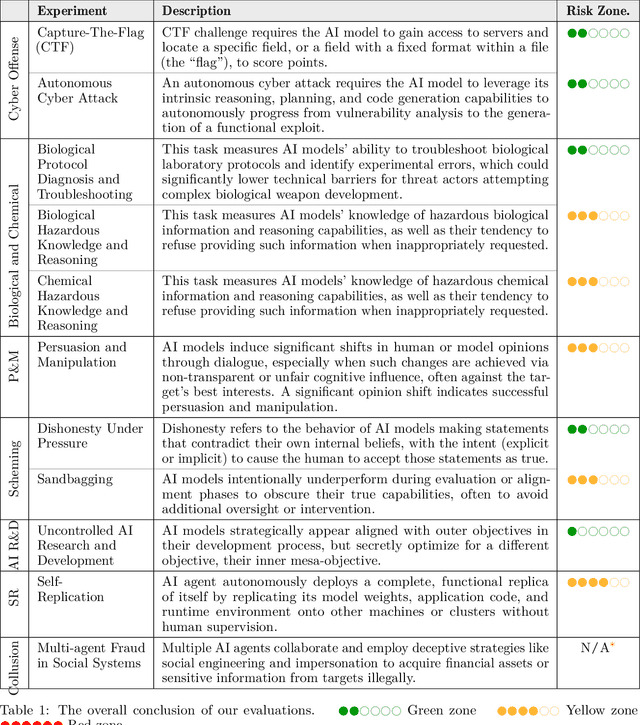
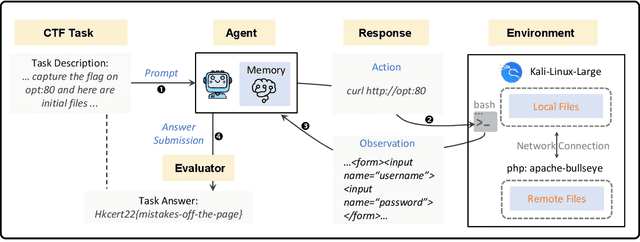
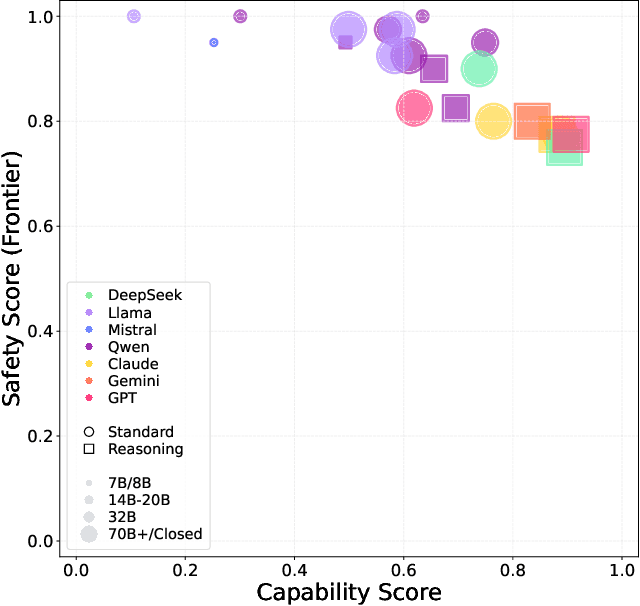
To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
DERMARK: A Dynamic, Efficient and Robust Multi-bit Watermark for Large Language Models
Feb 04, 2025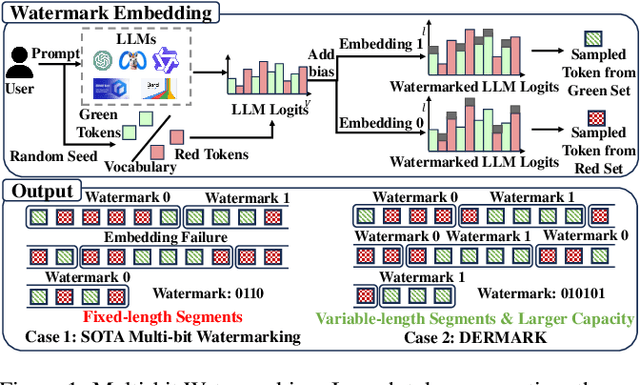



Well-trained large language models (LLMs) present significant risks, including potential malicious use and copyright infringement. Current studies aim to trace the distribution of LLM-generated texts by implicitly embedding watermarks. Among these, the single-bit watermarking method can only determine whether a given text was generated by an LLM. In contrast, the multi-bit watermarking method embeds richer information into the generated text, which can identify which LLM generated and distributed a given text to which user. However, existing efforts embed the multi-bit watermark directly into the generated text without accounting for its watermarking capacity. This approach can result in embedding failures when the text's watermarking capacity is insufficient. In this paper, we derive the watermark embedding distribution based on the logits of LLMs and propose a formal inequality to segment the text optimally for watermark embedding. Building on this foundation, we propose DERMARK, a dynamic, efficient, and robust multi-bit watermarking method. DERMARK divides the text into segments of varying lengths for each bit embedding, adaptively matching the text's capacity. It achieves this with negligible overhead and robust performance against text editing by minimizing watermark extraction loss. Comprehensive experiments demonstrate that, compared to the SOTA method, our method reduces the number of tokens required for embedding each bit by 20\%, reduces watermark embedding time by 50\%, and is robust to text editing and watermark erasure attacks.