 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Dynamic Heterogeneous Graph and Node Importance for Future Citation Prediction
May 27, 2023



Accurate citation count prediction of newly published papers could help editors and readers rapidly figure out the influential papers in the future. Though many approaches are proposed to predict a paper's future citation, most ignore the dynamic heterogeneous graph structure or node importance in academic networks. To cope with this problem, we propose a Dynamic heterogeneous Graph and Node Importance network (DGNI) learning framework, which fully leverages the dynamic heterogeneous graph and node importance information to predict future citation trends of newly published papers. First, a dynamic heterogeneous network embedding module is provided to capture the dynamic evolutionary trends of the whole academic network. Then, a node importance embedding module is proposed to capture the global consistency relationship to figure out each paper's node importance. Finally, the dynamic evolutionary trend embeddings and node importance embeddings calculated above are combined to jointly predict the future citation counts of each paper, by a log-normal distribution model according to multi-faced paper node representations. Extensive experiments on two large-scale datasets demonstrate that our model significantly improves all indicators compared to the SOTA models.
RHCO: A Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning for Large-scale Graphs
Nov 20, 2022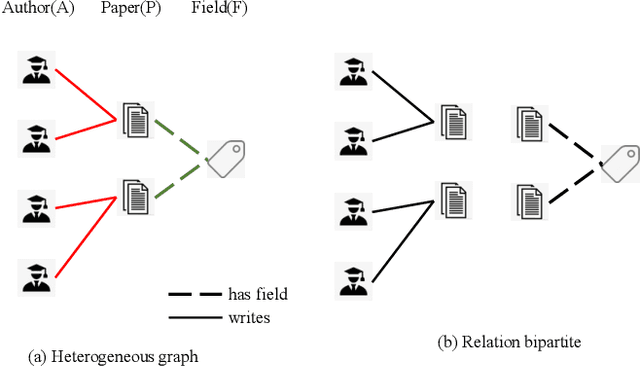
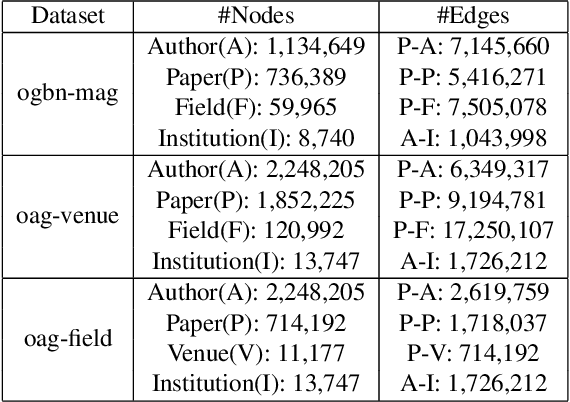
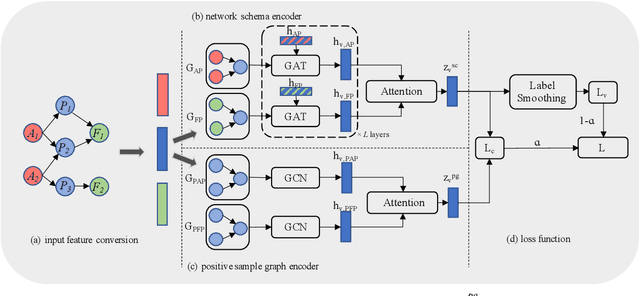
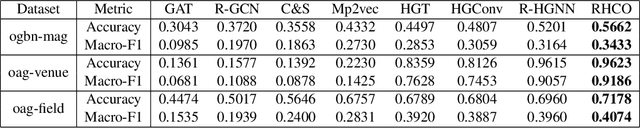
Heterogeneous graph neural networks (HGNNs) have been widely applied in heterogeneous information network tasks, while most HGNNs suffer from poor scalability or weak representation when they are applied to large-scale heterogeneous graphs. To address these problems, we propose a novel Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning (RHCO) for large-scale heterogeneous graph representation learning. Unlike traditional heterogeneous graph neural networks, we adopt the contrastive learning mechanism to deal with the complex heterogeneity of large-scale heterogeneous graphs. We first learn relation-aware node embeddings under the network schema view. Then we propose a novel positive sample selection strategy to choose meaningful positive samples. After learning node embeddings under the positive sample graph view, we perform a cross-view contrastive learning to obtain the final node representations. Moreover, we adopt the label smoothing technique to boost the performance of RHCO. Extensive experiments on three large-scale academic heterogeneous graph datasets show that RHCO achieves best performance over the state-of-the-art models.