 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightXML: Transformer with Dynamic Negative Sampling for High-Performance Extreme Multi-label Text Classification
Jan 09, 2021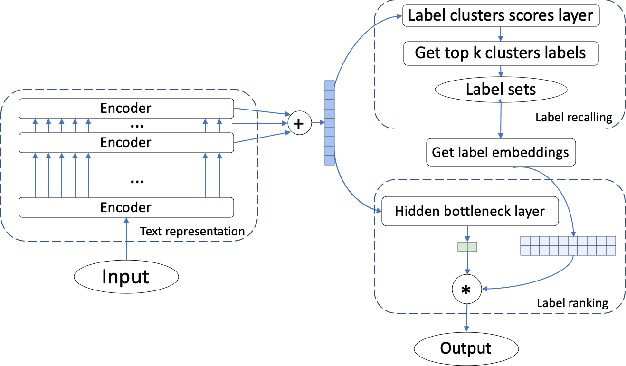
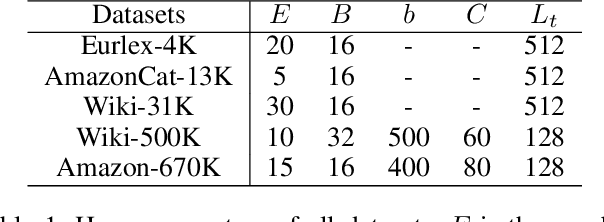


Extreme Multi-label text Classification (XMC) is a task of finding the most relevant labels from a large label set. Nowadays deep learning-based methods have shown significant success in XMC. However, the existing methods (e.g., AttentionXML and X-Transformer etc) still suffer from 1) combining several models to train and predict for one dataset, and 2) sampling negative labels statically during the process of training label ranking model, which reduces both the efficiency and accuracy of the model. To address the above problems, we proposed LightXML, which adopts end-to-end training and dynamic negative labels sampling. In LightXML, we use generative cooperative networks to recall and rank labels, in which label recalling part generates negative and positive labels, and label ranking part distinguishes positive labels from these labels. Through these networks, negative labels are sampled dynamically during label ranking part training by feeding with the same text representation. Extensive experiments show that LightXML outperforms state-of-the-art methods in five extreme multi-label datasets with much smaller model size and lower computational complexity. In particular, on the Amazon dataset with 670K labels, LightXML can reduce the model size up to 72% compared to AttentionXML.