 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCS-CTC: Leveraging Soft Alignments to Enhance Phonetic Transcription Robustness
Aug 05, 2025Phonetic speech transcription is crucial for fine-grained linguistic analysis and downstream speech applications. While Connectionist Temporal Classification (CTC) is a widely used approach for such tasks due to its efficiency, it often falls short in recognition performance, especially under unclear and nonfluent speech. In this work, we propose LCS-CTC, a two-stage framework for phoneme-level speech recognition that combines a similarity-aware local alignment algorithm with a constrained CTC training objective. By predicting fine-grained frame-phoneme cost matrices and applying a modified Longest Common Subsequence (LCS) algorithm, our method identifies high-confidence alignment zones which are used to constrain the CTC decoding path space, thereby reducing overfitting and improving generalization ability, which enables both robust recognition and text-free forced alignment. Experiments on both LibriSpeech and PPA demonstrate that LCS-CTC consistently outperforms vanilla CTC baselines, suggesting its potential to unify phoneme modeling across fluent and non-fluent speech.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
Eurekaverse: Environment Curriculum Generation via Large Language Models
Nov 04, 2024
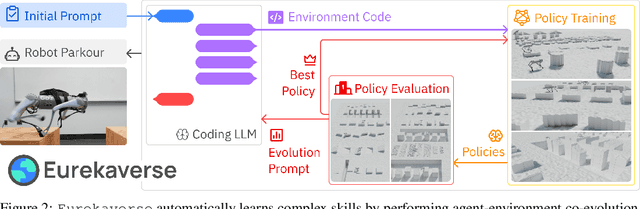

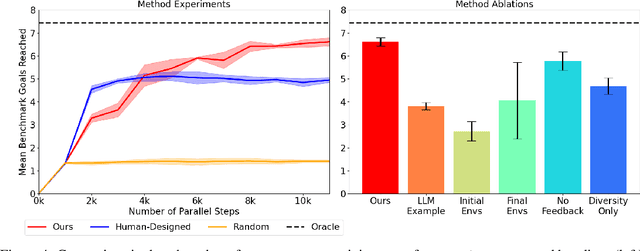
Recent work has demonstrated that a promising strategy for teaching robots a wide range of complex skills is by training them on a curriculum of progressively more challenging environments. However, developing an effective curriculum of environment distributions currently requires significant expertise, which must be repeated for every new domain. Our key insight is that environments are often naturally represented as code. Thus, we probe whether effective environment curriculum design can be achieved and automated via code generation by large language models (LLM). In this paper, we introduce Eurekaverse, an unsupervised environment design algorithm that uses LLMs to sample progressively more challenging, diverse, and learnable environments for skill training. We validate Eurekaverse's effectiveness in the domain of quadrupedal parkour learning, in which a quadruped robot must traverse through a variety of obstacle courses. The automatic curriculum designed by Eurekaverse enables gradual learning of complex parkour skills in simulation and can successfully transfer to the real-world, outperforming manual training courses designed by humans.
DrEureka: Language Model Guided Sim-To-Real Transfer
Jun 04, 2024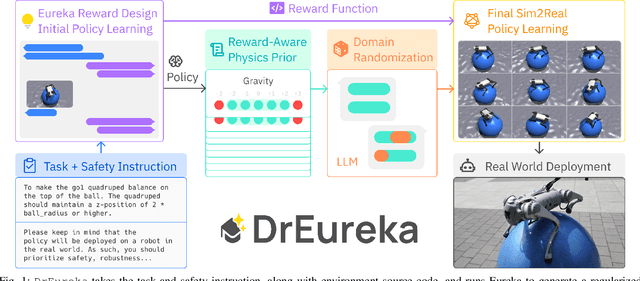
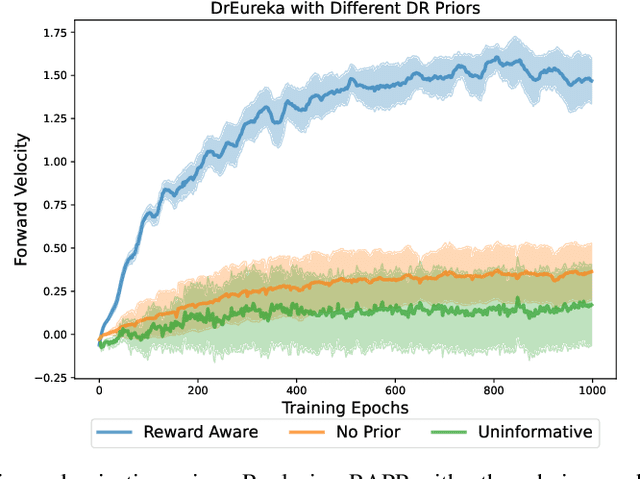

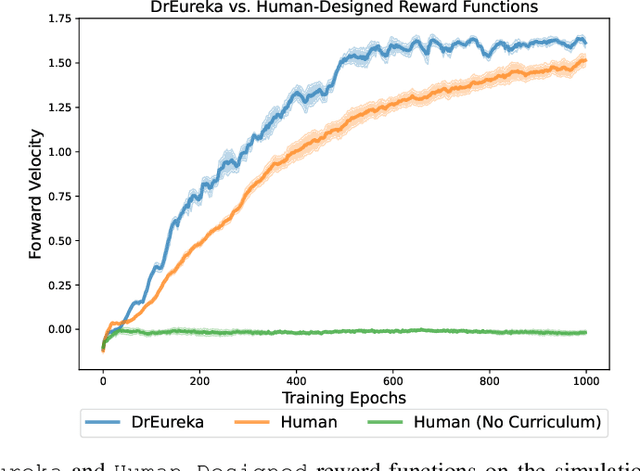
Transferring policies learned in simulation to the real world is a promising strategy for acquiring robot skills at scale. However, sim-to-real approaches typically rely on manual design and tuning of the task reward function as well as the simulation physics parameters, rendering the process slow and human-labor intensive. In this paper, we investigate using Large Language Models (LLMs) to automate and accelerate sim-to-real design. Our LLM-guided sim-to-real approach, DrEureka, requires only the physics simulation for the target task and automatically constructs suitable reward functions and domain randomization distributions to support real-world transfer. We first demonstrate that our approach can discover sim-to-real configurations that are competitive with existing human-designed ones on quadruped locomotion and dexterous manipulation tasks. Then, we showcase that our approach is capable of solving novel robot tasks, such as quadruped balancing and walking atop a yoga ball, without iterative manual design.
Generalization Analogies: A Testbed for Generalizing AI Oversight to Hard-To-Measure Domains
Nov 19, 2023As AI systems become more intelligent and their behavior becomes more challenging to assess, they may learn to game the flaws of human feedback instead of genuinely striving to follow instructions; however, this risk can be mitigated by controlling how LLMs generalize human feedback to situations where it is unreliable. To better understand how reward models generalize, we craft 69 distribution shifts spanning 8 categories. We find that reward models do not learn to evaluate `instruction-following' by default and instead favor personas that resemble internet text. Techniques for interpreting reward models' internal representations achieve better generalization than standard fine-tuning, but still frequently fail to distinguish instruction-following from conflated behaviors. We consolidate the 15 most challenging distribution shifts into the GENeralization analogIES (GENIES) benchmark, which we hope will enable progress toward controlling reward model generalization.