 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprovisation through Physical Understanding: Using Novel Objects as Tools with Visual Foresight
Paper and Code
Apr 11, 2019
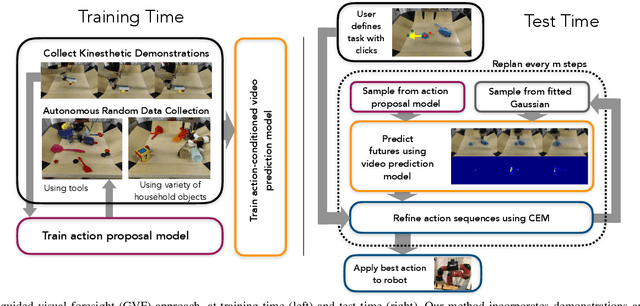


Machine learning techniques have enabled robots to learn narrow, yet complex tasks and also perform broad, yet simple skills with a wide variety of objects. However, learning a model that can both perform complex tasks and generalize to previously unseen objects and goals remains a significant challenge. We study this challenge in the context of "improvisational" tool use: a robot is presented with novel objects and a user-specified goal (e.g., sweep some clutter into the dustpan), and must figure out, using only raw image observations, how to accomplish the goal using the available objects as tools. We approach this problem by training a model with both a visual and physical understanding of multi-object interactions, and develop a sampling-based optimizer that can leverage these interactions to accomplish tasks. We do so by combining diverse demonstration data with self-supervised interaction data, aiming to leverage the interaction data to build generalizable models and the demonstration data to guide the model-based RL planner to solve complex tasks. Our experiments show that our approach can solve a variety of complex tool use tasks from raw pixel inputs, outperforming both imitation learning and self-supervised learning individually. Furthermore, we show that the robot can perceive and use novel objects as tools, including objects that are not conventional tools, while also choosing dynamically to use or not use tools depending on whether or not they are required.