 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-centric Video Prediction without Annotation
Paper and Code
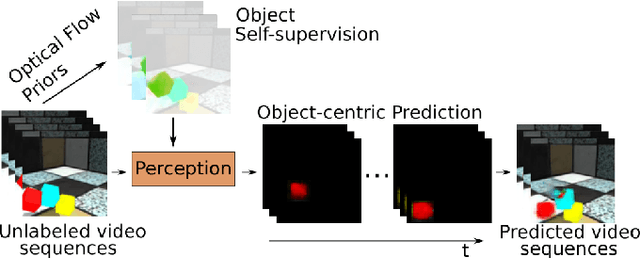
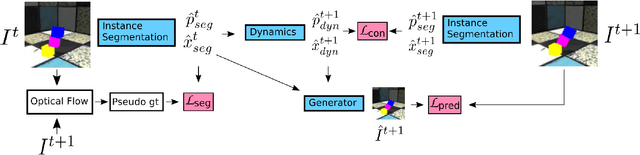

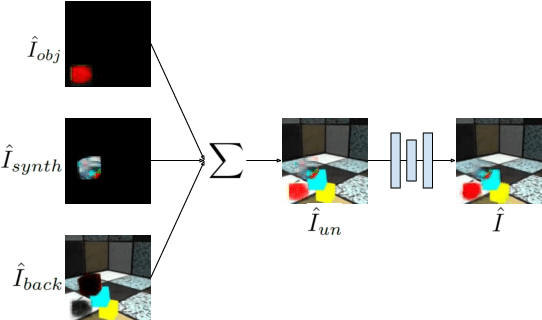
In order to interact with the world, agents must be able to predict the results of the world's dynamics. A natural approach to learn about these dynamics is through video prediction, as cameras are ubiquitous and powerful sensors. Direct pixel-to-pixel video prediction is difficult, does not take advantage of known priors, and does not provide an easy interface to utilize the learned dynamics. Object-centric video prediction offers a solution to these problems by taking advantage of the simple prior that the world is made of objects and by providing a more natural interface for control. However, existing object-centric video prediction pipelines require dense object annotations in training video sequences. In this work, we present Object-centric Prediction without Annotation (OPA), an object-centric video prediction method that takes advantage of priors from powerful computer vision models. We validate our method on a dataset comprised of video sequences of stacked objects falling, and demonstrate how to adapt a perception model in an environment through end-to-end video prediction training.