 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Twin Generators for Disease Modeling
May 02, 2024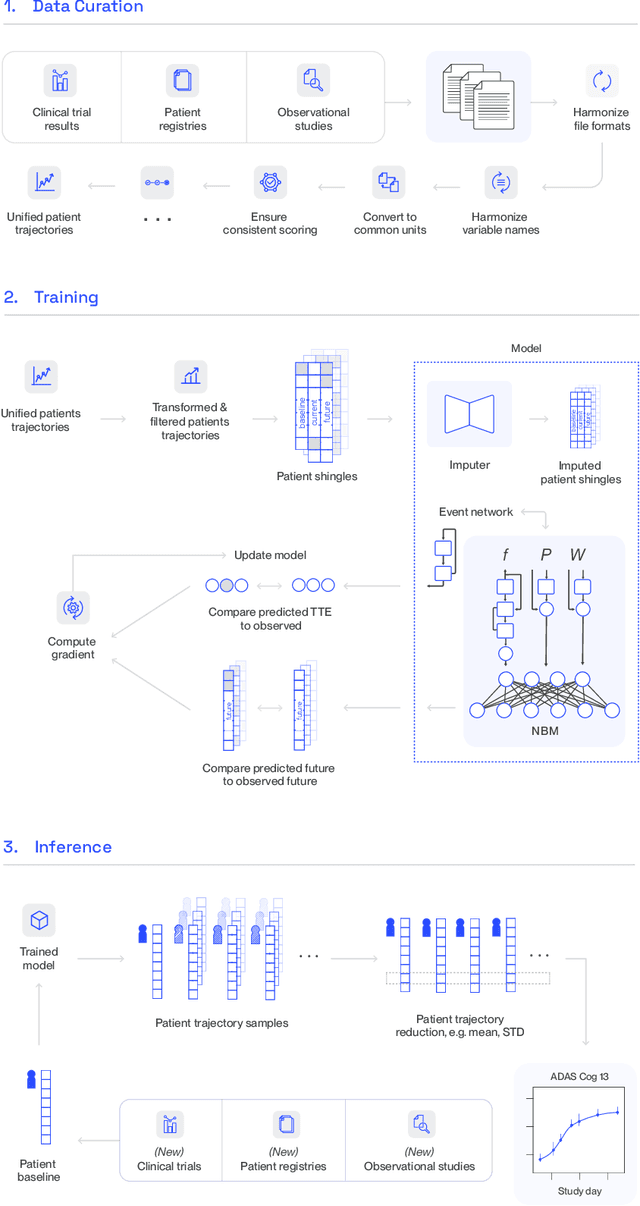
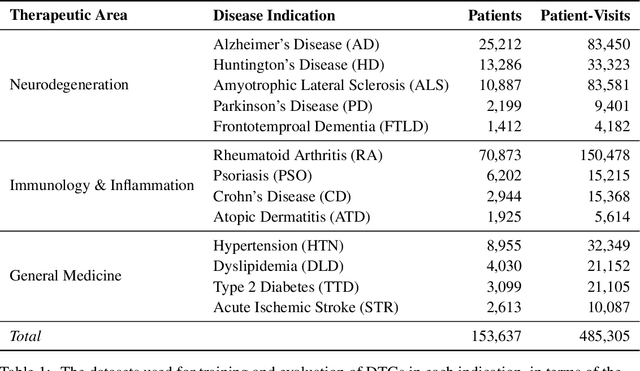
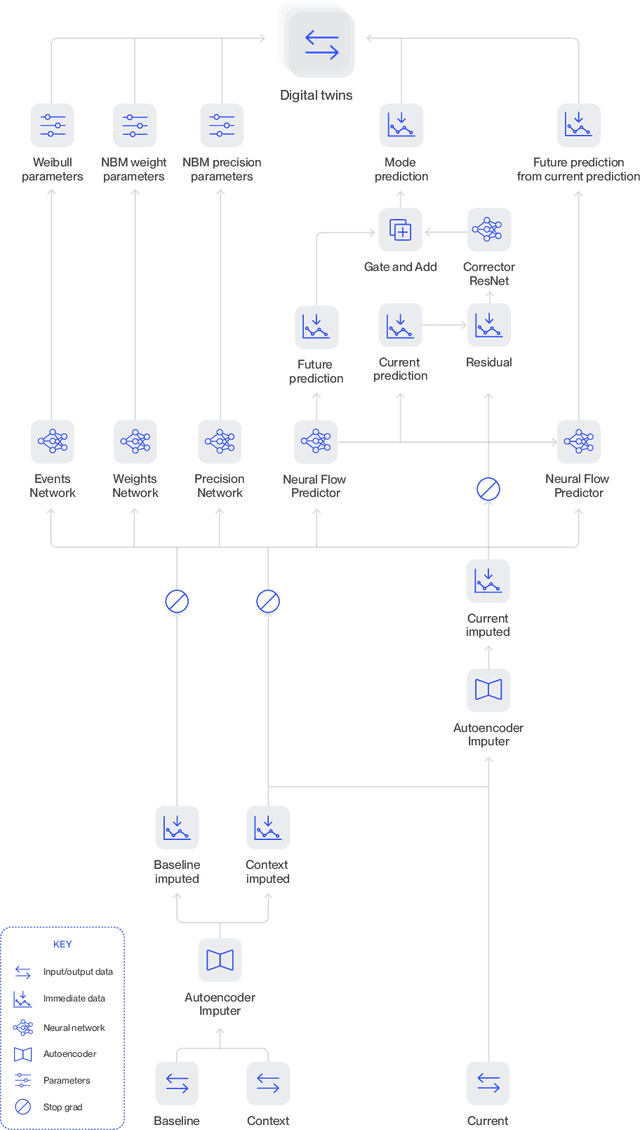
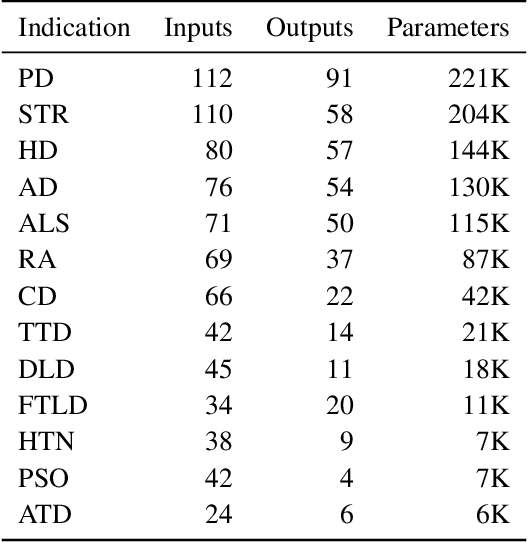
A patient's digital twin is a computational model that describes the evolution of their health over time. Digital twins have the potential to revolutionize medicine by enabling individual-level computer simulations of human health, which can be used to conduct more efficient clinical trials or to recommend personalized treatment options. Due to the overwhelming complexity of human biology, machine learning approaches that leverage large datasets of historical patients' longitudinal health records to generate patients' digital twins are more tractable than potential mechanistic models. In this manuscript, we describe a neural network architecture that can learn conditional generative models of clinical trajectories, which we call Digital Twin Generators (DTGs), that can create digital twins of individual patients. We show that the same neural network architecture can be trained to generate accurate digital twins for patients across 13 different indications simply by changing the training set and tuning hyperparameters. By introducing a general purpose architecture, we aim to unlock the ability to scale machine learning approaches to larger datasets and across more indications so that a digital twin could be created for any patient in the world.
Prognostic Covariate Adjustment for Logistic Regression in Randomized Controlled Trials
Feb 29, 2024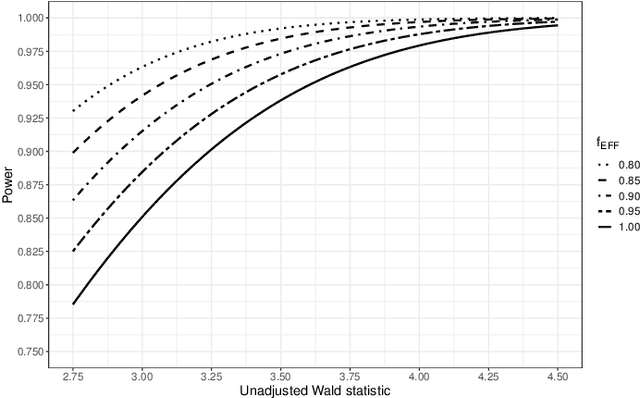

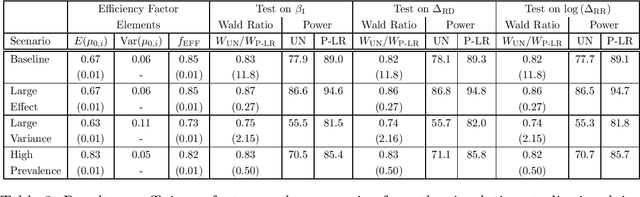
Randomized controlled trials (RCTs) with binary primary endpoints introduce novel challenges for inferring the causal effects of treatments. The most significant challenge is non-collapsibility, in which the conditional odds ratio estimand under covariate adjustment differs from the unconditional estimand in the logistic regression analysis of RCT data. This issue gives rise to apparent paradoxes, such as the variance of the estimator for the conditional odds ratio from a covariate-adjusted model being greater than the variance of the estimator from the unadjusted model. We address this challenge in the context of adjustment based on predictions of control outcomes from generative artificial intelligence (AI) algorithms, which are referred to as prognostic scores. We demonstrate that prognostic score adjustment in logistic regression increases the power of the Wald test for the conditional odds ratio under a fixed sample size, or alternatively reduces the necessary sample size to achieve a desired power, compared to the unadjusted analysis. We derive formulae for prospective calculations of the power gain and sample size reduction that can result from adjustment for the prognostic score. Furthermore, we utilize g-computation to expand the scope of prognostic score adjustment to inferences on the marginal risk difference, relative risk, and odds ratio estimands. We demonstrate the validity of our formulae via extensive simulation studies that encompass different types of logistic regression model specifications. Our simulation studies also indicate how prognostic score adjustment can reduce the variance of g-computation estimators for the marginal estimands while maintaining frequentist properties such as asymptotic unbiasedness and Type I error rate control. Our methodology can ultimately enable more definitive and conclusive analyses for RCTs with binary primary endpoints.
A Weighted Prognostic Covariate Adjustment Method for Efficient and Powerful Treatment Effect Inferences in Randomized Controlled Trials
Sep 25, 2023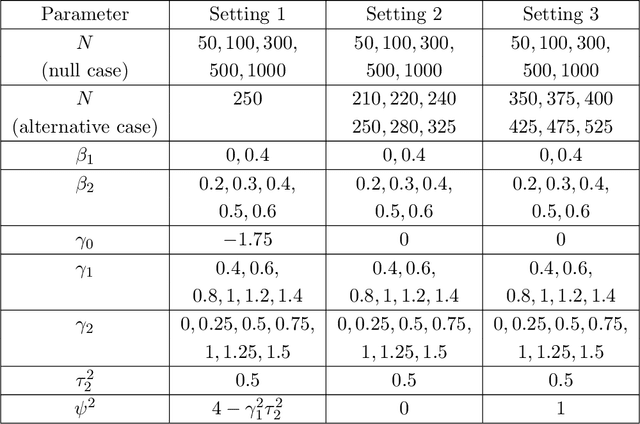
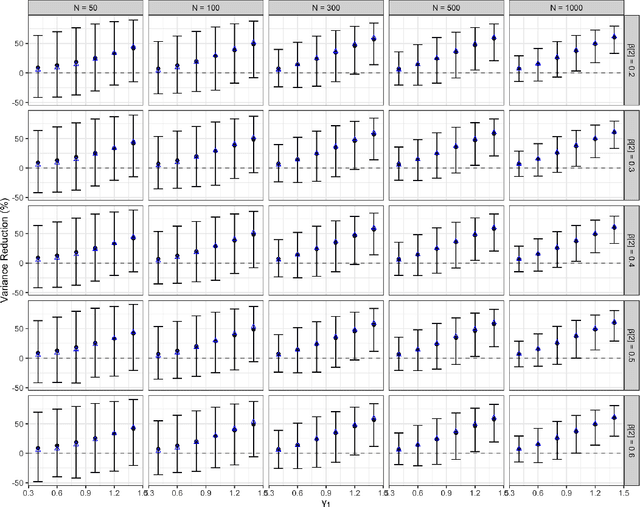

A crucial task for a randomized controlled trial (RCT) is to specify a statistical method that can yield an efficient estimator and powerful test for the treatment effect. A novel and effective strategy to obtain efficient and powerful treatment effect inferences is to incorporate predictions from generative artificial intelligence (AI) algorithms into covariate adjustment for the regression analysis of a RCT. Training a generative AI algorithm on historical control data enables one to construct a digital twin generator (DTG) for RCT participants, which utilizes a participant's baseline covariates to generate a probability distribution for their potential control outcome. Summaries of the probability distribution from the DTG are highly predictive of the trial outcome, and adjusting for these features via regression can thus improve the quality of treatment effect inferences, while satisfying regulatory guidelines on statistical analyses, for a RCT. However, a critical assumption in this strategy is homoskedasticity, or constant variance of the outcome conditional on the covariates. In the case of heteroskedasticity, existing covariate adjustment methods yield inefficient estimators and underpowered tests. We propose to address heteroskedasticity via a weighted prognostic covariate adjustment methodology (Weighted PROCOVA) that adjusts for both the mean and variance of the regression model using information obtained from the DTG. We prove that our method yields unbiased treatment effect estimators, and demonstrate via comprehensive simulation studies and case studies from Alzheimer's disease that it can reduce the variance of the treatment effect estimator, maintain the Type I error rate, and increase the power of the test for the treatment effect from 80% to 85%~90% when the variances from the DTG can explain 5%~10% of the variation in the RCT participants' outcomes.
Modeling Disease Progression in Mild Cognitive Impairment and Alzheimer's Disease with Digital Twins
Dec 24, 2020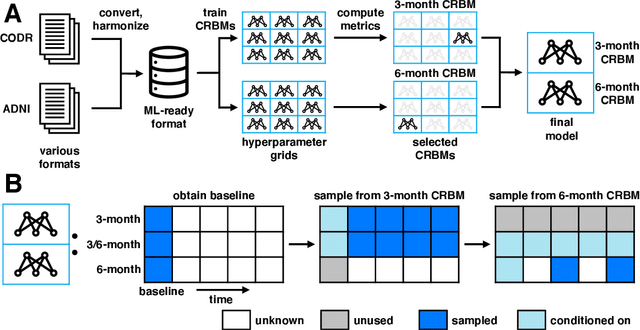

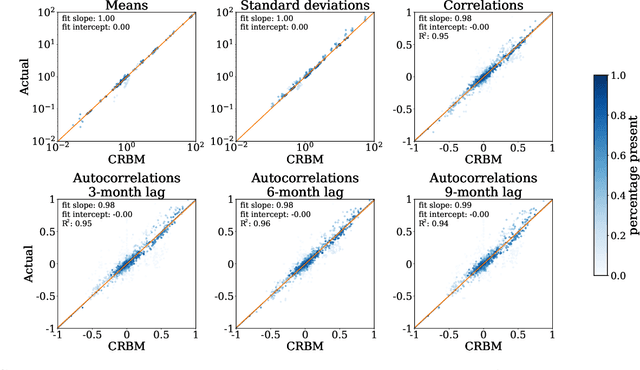
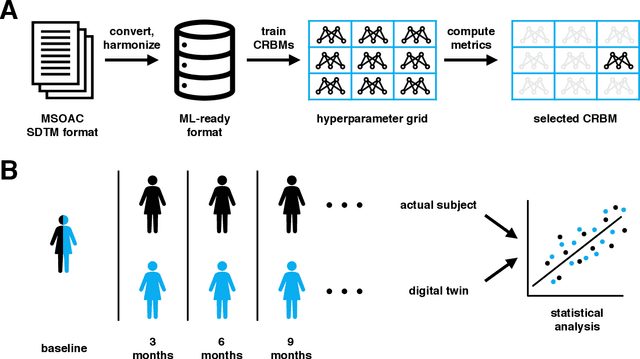
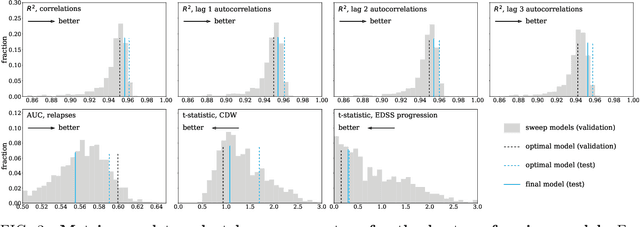
Alzheimer's Disease (AD) is a neurodegenerative disease that affects subjects in a broad range of severity and is assessed in clinical trials with multiple cognitive and functional instruments. As clinical trials in AD increasingly focus on earlier stages of the disease, especially Mild Cognitive Impairment (MCI), the ability to model subject outcomes across the disease spectrum is extremely important. We use unsupervised machine learning models called Conditional Restricted Boltzmann Machines (CRBMs) to create Digital Twins of AD subjects. Digital Twins are simulated clinical records that share baseline data with actual subjects and comprehensively model their outcomes under standard-of-care. The CRBMs are trained on a large set of records from subjects in observational studies and the placebo arms of clinical trials across the AD spectrum. These data exhibit a challenging, but common, patchwork of measured and missing observations across subjects in the dataset, and we present a novel model architecture designed to learn effectively from it. We evaluate performance against a held-out test dataset and show how Digital Twins simultaneously capture the progression of a number of key endpoints in clinical trials across a broad spectrum of disease severity, including MCI and mild-to-moderate AD.
Generating Digital Twins with Multiple Sclerosis Using Probabilistic Neural Networks
Feb 04, 2020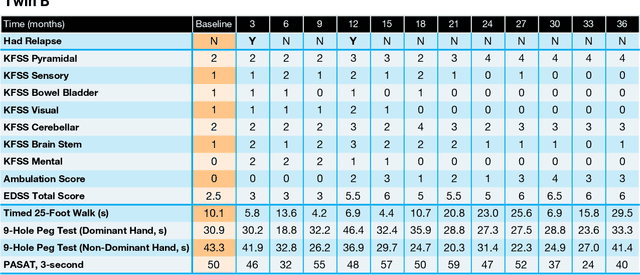
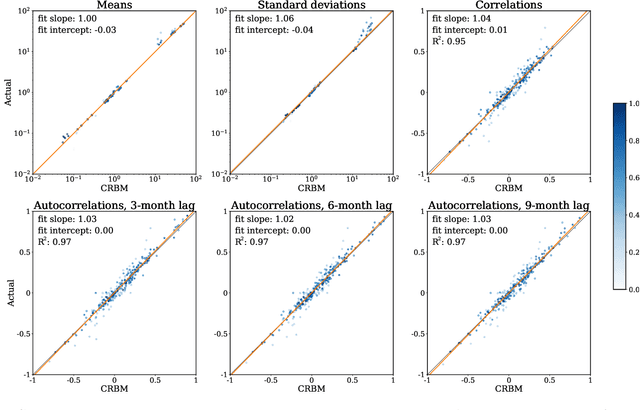
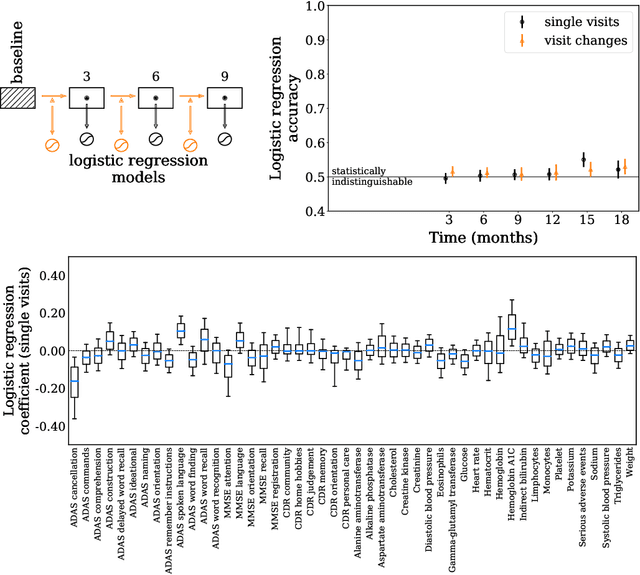
Multiple Sclerosis (MS) is a neurodegenerative disorder characterized by a complex set of clinical assessments. We use an unsupervised machine learning model called a Conditional Restricted Boltzmann Machine (CRBM) to learn the relationships between covariates commonly used to characterize subjects and their disease progression in MS clinical trials. A CRBM is capable of generating digital twins, which are simulated subjects having the same baseline data as actual subjects. Digital twins allow for subject-level statistical analyses of disease progression. The CRBM is trained using data from 2395 subjects enrolled in the placebo arms of clinical trials across the three primary subtypes of MS. We discuss how CRBMs are trained and show that digital twins generated by the model are statistically indistinguishable from their actual subject counterparts along a number of measures.
Using deep learning for comprehensive, personalized forecasting of Alzheimer's Disease progression
Jul 10, 2018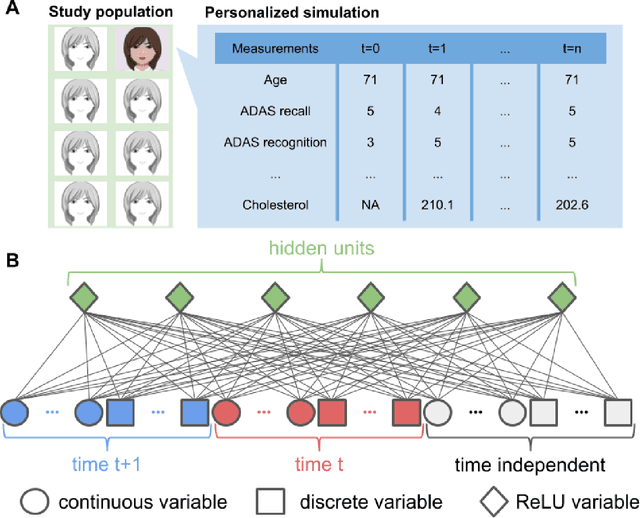
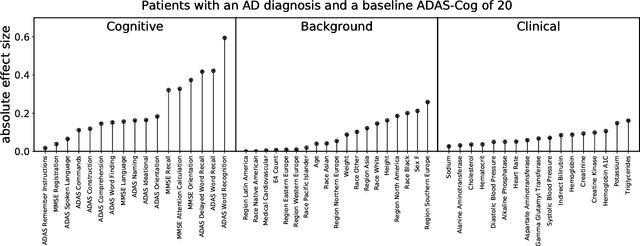
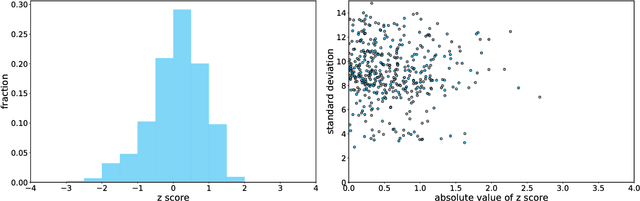
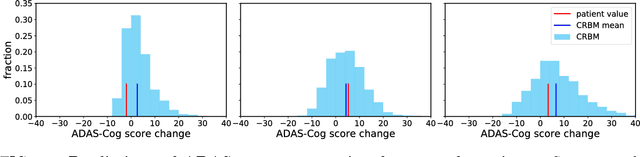
A patient is more than one number, yet most approaches to machine learning from electronic health data can only predict a single endpoint. Here, we present an alternative -- using unsupervised deep learning to simulate detailed patient trajectories. We use data comprising 18-month longitudinal trajectories of 42 clinical variables from 1908 patients with Mild Cognitive Impairment (MCI) or Alzheimer's Disease (AD) to train a model for personalized forecasting of disease progression. Our model simulates the evolution of each sub-component of cognitive exams, laboratory tests, and their associations with baseline clinical characteristics, generating both predictions and their confidence intervals. Even though it is not trained to predict changes in disease severity, our unsupervised model predicts changes in total ADAS-Cog scores with the same accuracy as specifically trained supervised models. We show how simulations can be used to interpret our model and demonstrate how to create synthetic control arm data for AD clinical trials. Our model's ability to simultaneously predict dozens of characteristics of a patient at any point in the future is a crucial step forward in computational precision medicine.
Boltzmann Encoded Adversarial Machines
Apr 23, 2018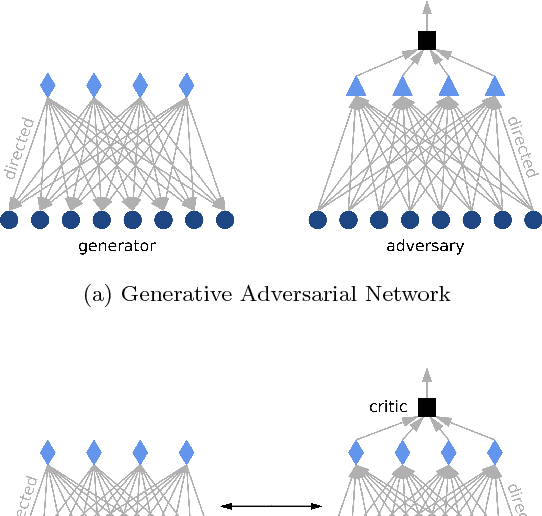
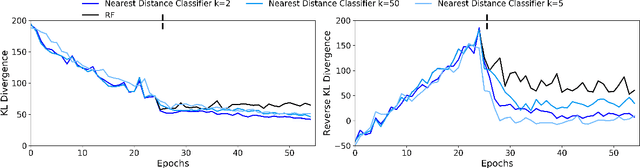


Restricted Boltzmann Machines (RBMs) are a class of generative neural network that are typically trained to maximize a log-likelihood objective function. We argue that likelihood-based training strategies may fail because the objective does not sufficiently penalize models that place a high probability in regions where the training data distribution has low probability. To overcome this problem, we introduce Boltzmann Encoded Adversarial Machines (BEAMs). A BEAM is an RBM trained against an adversary that uses the hidden layer activations of the RBM to discriminate between the training data and the probability distribution generated by the model. We present experiments demonstrating that BEAMs outperform RBMs and GANs on multiple benchmarks.