 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust AI-Synthesized Speech Detection Using Feature Decomposition Learning and Synthesizer Feature Augmentation
Paper and Code
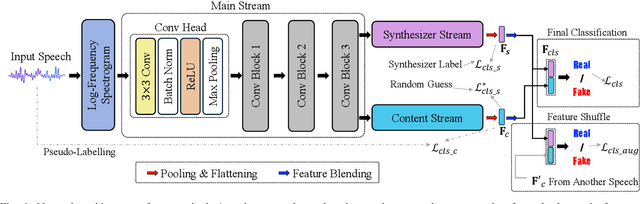
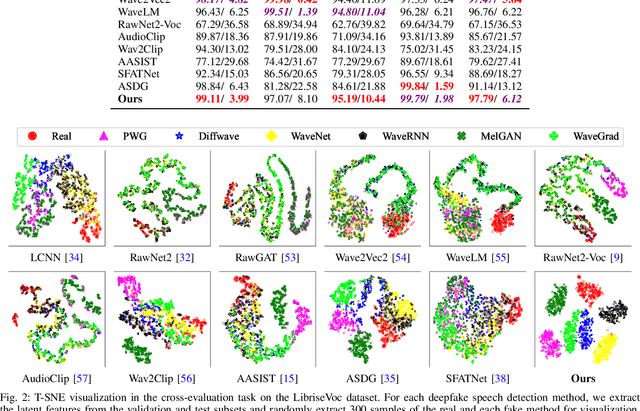
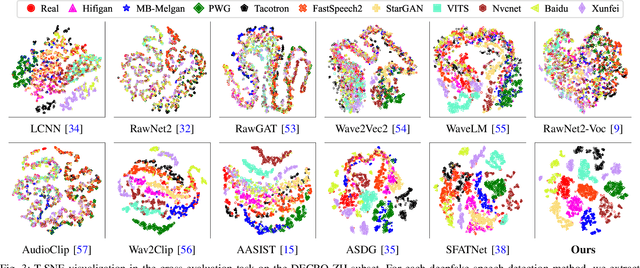
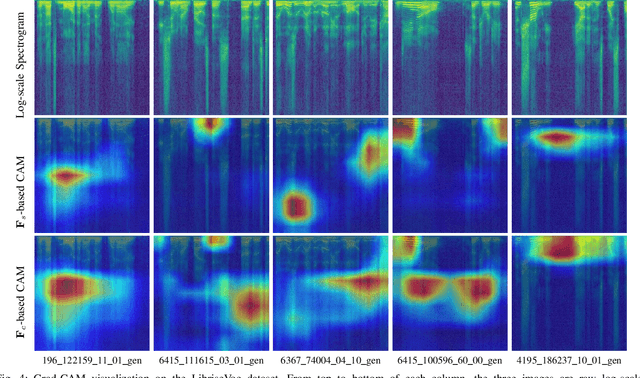
AI-synthesized speech, also known as deepfake speech, has recently raised significant concerns due to the rapid advancement of speech synthesis and speech conversion techniques. Previous works often rely on distinguishing synthesizer artifacts to identify deepfake speech. However, excessive reliance on these specific synthesizer artifacts may result in unsatisfactory performance when addressing speech signals created by unseen synthesizers. In this paper, we propose a robust deepfake speech detection method that employs feature decomposition to learn synthesizer-independent content features as complementary for detection. Specifically, we propose a dual-stream feature decomposition learning strategy that decomposes the learned speech representation using a synthesizer stream and a content stream. The synthesizer stream specializes in learning synthesizer features through supervised training with synthesizer labels. Meanwhile, the content stream focuses on learning synthesizer-independent content features, enabled by a pseudo-labeling-based supervised learning method. This method randomly transforms speech to generate speed and compression labels for training. Additionally, we employ an adversarial learning technique to reduce the synthesizer-related components in the content stream. The final classification is determined by concatenating the synthesizer and content features. To enhance the model's robustness to different synthesizer characteristics, we further propose a synthesizer feature augmentation strategy that randomly blends the characteristic styles within real and fake audio features and randomly shuffles the synthesizer features with the content features. This strategy effectively enhances the feature diversity and simulates more feature combinations.