 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Driven Traffic Anomaly Detection with Temporal High-Frequency Modeling in Driving Videos
Jan 07, 2024Traffic anomaly detection (TAD) in driving videos is critical for ensuring the safety of autonomous driving and advanced driver assistance systems. Previous single-stage TAD methods primarily rely on frame prediction, making them vulnerable to interference from dynamic backgrounds induced by the rapid movement of the dashboard camera. While two-stage TAD methods appear to be a natural solution to mitigate such interference by pre-extracting background-independent features (such as bounding boxes and optical flow) using perceptual algorithms, they are susceptible to the performance of first-stage perceptual algorithms and may result in error propagation. In this paper, we introduce TTHF, a novel single-stage method aligning video clips with text prompts, offering a new perspective on traffic anomaly detection. Unlike previous approaches, the supervised signal of our method is derived from languages rather than orthogonal one-hot vectors, providing a more comprehensive representation. Further, concerning visual representation, we propose to model the high frequency of driving videos in the temporal domain. This modeling captures the dynamic changes of driving scenes, enhances the perception of driving behavior, and significantly improves the detection of traffic anomalies. In addition, to better perceive various types of traffic anomalies, we carefully design an attentive anomaly focusing mechanism that visually and linguistically guides the model to adaptively focus on the visual context of interest, thereby facilitating the detection of traffic anomalies. It is shown that our proposed TTHF achieves promising performance, outperforming state-of-the-art competitors by +5.4% AUC on the DoTA dataset and achieving high generalization on the DADA dataset.
A Memory-Augmented Multi-Task Collaborative Framework for Unsupervised Traffic Accident Detection in Driving Videos
Jul 27, 2023



Identifying traffic accidents in driving videos is crucial to ensuring the safety of autonomous driving and driver assistance systems. To address the potential danger caused by the long-tailed distribution of driving events, existing traffic accident detection (TAD) methods mainly rely on unsupervised learning. However, TAD is still challenging due to the rapid movement of cameras and dynamic scenes in driving scenarios. Existing unsupervised TAD methods mainly rely on a single pretext task, i.e., an appearance-based or future object localization task, to detect accidents. However, appearance-based approaches are easily disturbed by the rapid movement of the camera and changes in illumination, which significantly reduce the performance of traffic accident detection. Methods based on future object localization may fail to capture appearance changes in video frames, making it difficult to detect ego-involved accidents (e.g., out of control of the ego-vehicle). In this paper, we propose a novel memory-augmented multi-task collaborative framework (MAMTCF) for unsupervised traffic accident detection in driving videos. Different from previous approaches, our method can more accurately detect both ego-involved and non-ego accidents by simultaneously modeling appearance changes and object motions in video frames through the collaboration of optical flow reconstruction and future object localization tasks. Further, we introduce a memory-augmented motion representation mechanism to fully explore the interrelation between different types of motion representations and exploit the high-level features of normal traffic patterns stored in memory to augment motion representations, thus enlarging the difference from anomalies. Experimental results on recently published large-scale dataset demonstrate that our method achieves better performance compared to previous state-of-the-art approaches.
STGlow: A Flow-based Generative Framework with Dual Graphormer for Pedestrian Trajectory Prediction
Nov 22, 2022Pedestrian trajectory prediction task is an essential component of intelligent systems, and its applications include but are not limited to autonomous driving, robot navigation, and anomaly detection of monitoring systems. Due to the diversity of motion behaviors and the complex social interactions among pedestrians, accurately forecasting the future trajectory of pedestrians is challenging. Existing approaches commonly adopt GANs or CVAEs to generate diverse trajectories. However, GAN-based methods do not directly model data in a latent space, which makes them fail to have full support over the underlying data distribution; CVAE-based methods optimize a lower bound on the log-likelihood of observations, causing the learned distribution to deviate from the underlying distribution. The above limitations make existing approaches often generate highly biased or unnatural trajectories. In this paper, we propose a novel generative flow based framework with dual graphormer for pedestrian trajectory prediction (STGlow). Different from previous approaches, our method can more accurately model the underlying data distribution by optimizing the exact log-likelihood of motion behaviors. Besides, our method has clear physical meanings to simulate the evolution of human motion behaviors, where the forward process of the flow gradually degrades the complex motion behavior into a simple behavior, while its reverse process represents the evolution of a simple behavior to the complex motion behavior. Further, we introduce a dual graphormer combining with the graph structure to more adequately model the temporal dependencies and the mutual spatial interactions. Experimental results on several benchmarks demonstrate that our method achieves much better performance compared to previous state-of-the-art approaches.
Temporal Pyramid Network for Pedestrian Trajectory Prediction with Multi-Supervision
Dec 04, 2020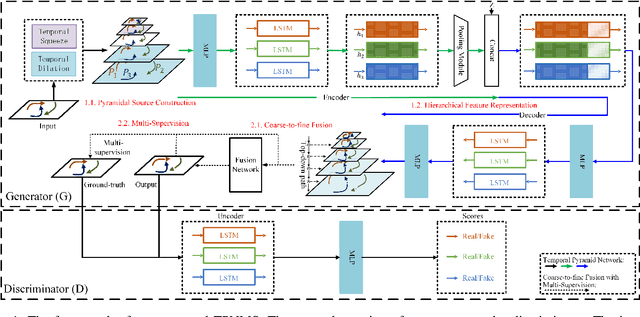



Predicting human motion behavior in a crowd is important for many applications, ranging from the natural navigation of autonomous vehicles to intelligent security systems of video surveillance. All the previous works model and predict the trajectory with a single resolution, which is rather inefficient and difficult to simultaneously exploit the long-range information (e.g., the destination of the trajectory), and the short-range information (e.g., the walking direction and speed at a certain time) of the motion behavior. In this paper, we propose a temporal pyramid network for pedestrian trajectory prediction through a squeeze modulation and a dilation modulation. Our hierarchical framework builds a feature pyramid with increasingly richer temporal information from top to bottom, which can better capture the motion behavior at various tempos. Furthermore, we propose a coarse-to-fine fusion strategy with multi-supervision. By progressively merging the top coarse features of global context to the bottom fine features of rich local context, our method can fully exploit both the long-range and short-range information of the trajectory. Experimental results on several benchmarks demonstrate the superiority of our method.