 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Blocks: Continuous Low-Rank Decomposed Scaling for Unified LLM Quantization and Adaptation
Jan 30, 2026Current quantization methods for LLMs predominantly rely on block-wise structures to maintain efficiency, often at the cost of representational flexibility. In this work, we demonstrate that element-wise quantization can be made as efficient as block-wise scaling while providing strictly superior expressive power by modeling the scaling manifold as continuous low-rank matrices ($S = BA$). We propose Low-Rank Decomposed Scaling (LoRDS), a unified framework that rethinks quantization granularity through this low-rank decomposition. By "breaking the blocks" of spatial constraints, LoRDS establishes a seamless efficiency lifecycle: it provides high-fidelity PTQ initialization refined via iterative optimization, enables joint QAT of weights and scaling factors, and facilitates high-rank multiplicative PEFT adaptation. Unlike additive PEFT approaches such as QLoRA, LoRDS enables high-rank weight updates within a low-rank budget while incurring no additional inference overhead. Supported by highly optimized Triton kernels, LoRDS consistently outperforms state-of-the-art baselines across various model families in both quantization and downstream fine-tuning tasks. Notably, on Llama3-8B, our method achieves up to a 27.0% accuracy improvement at 3 bits over NormalFloat quantization and delivers a 1.5x inference speedup on NVIDIA RTX 4090 while enhancing PEFT performance by 9.6% on downstream tasks over 4bit QLoRA, offering a robust and integrated solution for unified compression and adaptation of LLMs.
NaRLE: Natural Language Models using Reinforcement Learning with Emotion Feedback
Oct 05, 2021
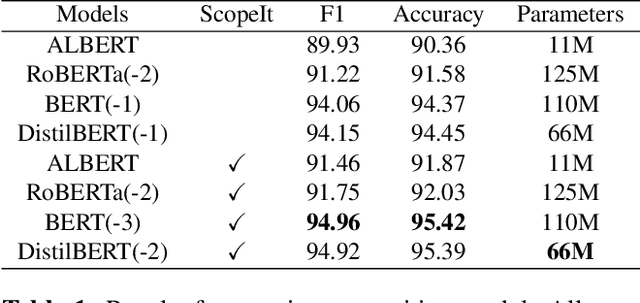

Current research in dialogue systems is focused on conversational assistants working on short conversations in either task-oriented or open domain settings. In this paper, we focus on improving task-based conversational assistants online, primarily those working on document-type conversations (e.g., emails) whose contents may or may not be completely related to the assistant's task. We propose "NARLE" a deep reinforcement learning (RL) framework for improving the natural language understanding (NLU) component of dialogue systems online without the need to collect human labels for customer data. The proposed solution associates user emotion with the assistant's action and uses that to improve NLU models using policy gradients. For two intent classification problems, we empirically show that using reinforcement learning to fine tune the pre-trained supervised learning models improves performance up to 43%. Furthermore, we demonstrate the robustness of the method to partial and noisy implicit feedback.