 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCTrans: Simplifying and Improving Crowd Counting with Transformer
Paper and Code
Sep 29, 2021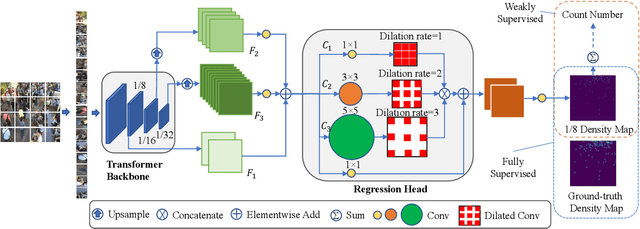



Most recent methods used for crowd counting are based on the convolutional neural network (CNN), which has a strong ability to extract local features. But CNN inherently fails in modeling the global context due to the limited receptive fields. However, the transformer can model the global context easily. In this paper, we propose a simple approach called CCTrans to simplify the design pipeline. Specifically, we utilize a pyramid vision transformer backbone to capture the global crowd information, a pyramid feature aggregation (PFA) model to combine low-level and high-level features, an efficient regression head with multi-scale dilated convolution (MDC) to predict density maps. Besides, we tailor the loss functions for our pipeline. Without bells and whistles, extensive experiments demonstrate that our method achieves new state-of-the-art results on several benchmarks both in weakly and fully-supervised crowd counting. Moreover, we currently rank No.1 on the leaderboard of NWPU-Crowd. Our code will be made available.