 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid In-memory Computing Architecture for the Training of Deep Neural Networks
Paper and Code
Feb 10, 2021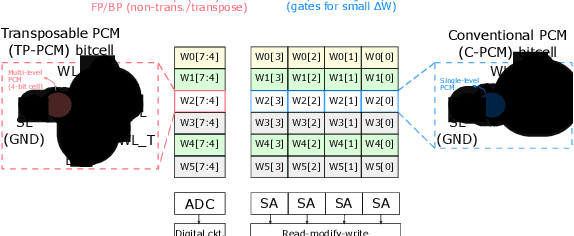



The cost involved in training deep neural networks (DNNs) on von-Neumann architectures has motivated the development of novel solutions for efficient DNN training accelerators. We propose a hybrid in-memory computing (HIC) architecture for the training of DNNs on hardware accelerators that results in memory-efficient inference and outperforms baseline software accuracy in benchmark tasks. We introduce a weight representation technique that exploits both binary and multi-level phase-change memory (PCM) devices, and this leads to a memory-efficient inference accelerator. Unlike previous in-memory computing-based implementations, we use a low precision weight update accumulator that results in more memory savings. We trained the ResNet-32 network to classify CIFAR-10 images using HIC. For a comparable model size, HIC-based training outperforms baseline network, trained in floating-point 32-bit (FP32) precision, by leveraging appropriate network width multiplier. Furthermore, we observe that HIC-based training results in about 50% less inference model size to achieve baseline comparable accuracy. We also show that the temporal drift in PCM devices has a negligible effect on post-training inference accuracy for extended periods (year). Finally, our simulations indicate HIC-based training naturally ensures that the number of write-erase cycles seen by the devices is a small fraction of the endurance limit of PCM, demonstrating the feasibility of this architecture for achieving hardware platforms that can learn in the field.