 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIPE: A Metric Independent Pipeline for Effective Code-Mixed NLG Evaluation
Jul 24, 2021
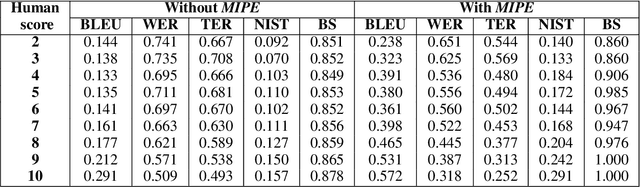
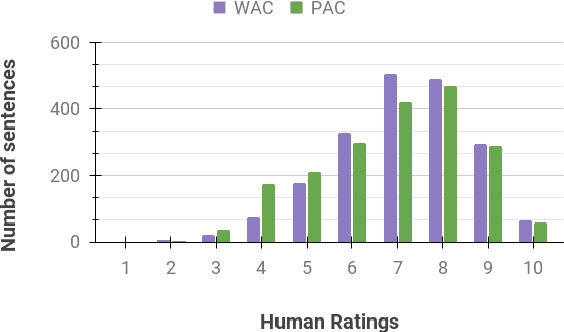
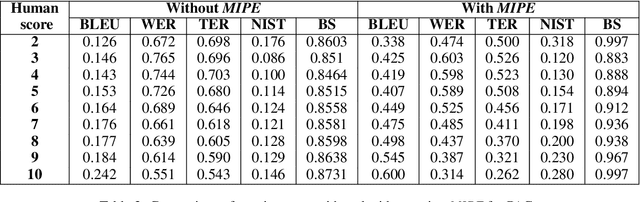
Code-mixing is a phenomenon of mixing words and phrases from two or more languages in a single utterance of speech and text. Due to the high linguistic diversity, code-mixing presents several challenges in evaluating standard natural language generation (NLG) tasks. Various widely popular metrics perform poorly with the code-mixed NLG tasks. To address this challenge, we present a metric independent evaluation pipeline MIPE that significantly improves the correlation between evaluation metrics and human judgments on the generated code-mixed text. As a use case, we demonstrate the performance of MIPE on the machine-generated Hinglish (code-mixing of Hindi and English languages) sentences from the HinGE corpus. We can extend the proposed evaluation strategy to other code-mixed language pairs, NLG tasks, and evaluation metrics with minimal to no effort.