 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving code-mixed hate detection by native sample mixing: A case study for Hindi-English code-mixed scenario
Paper and Code



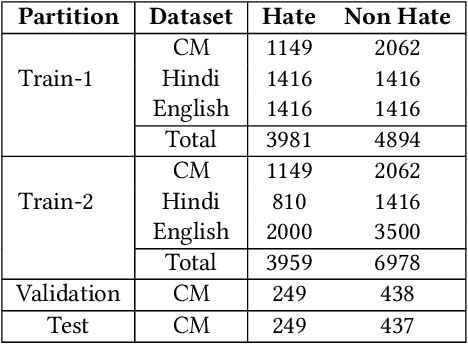
Hate detection has long been a challenging task for the NLP community. The task becomes complex in a code-mixed environment because the models must understand the context and the hate expressed through language alteration. Compared to the monolingual setup, we see very less work on code-mixed hate as large-scale annotated hate corpora are unavailable to make the study. To overcome this bottleneck, we propose using native language hate samples. We hypothesise that in the era of multilingual language models (MLMs), hate in code-mixed settings can be detected by majorly relying on the native language samples. Even though the NLP literature reports the effectiveness of MLMs on hate detection in many cross-lingual settings, their extensive evaluation in a code-mixed scenario is yet to be done. This paper attempts to fill this gap through rigorous empirical experiments. We considered the Hindi-English code-mixed setup as a case study as we have the linguistic expertise for the same. Some of the interesting observations we got are: (i) adding native hate samples in the code-mixed training set, even in small quantity, improved the performance of MLMs for code-mixed hate detection, (ii) MLMs trained with native samples alone observed to be detecting code-mixed hate to a large extent, (iii) The visualisation of attention scores revealed that, when native samples were included in training, MLMs could better focus on the hate emitting words in the code-mixed context, and (iv) finally, when hate is subjective or sarcastic, naively mixing native samples doesn't help much to detect code-mixed hate. We will release the data and code repository to reproduce the reported results.