 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Agent Selection and Interaction Network for Image-to-point cloud Registration
Nov 08, 2025Typical detection-free methods for image-to-point cloud registration leverage transformer-based architectures to aggregate cross-modal features and establish correspondences. However, they often struggle under challenging conditions, where noise disrupts similarity computation and leads to incorrect correspondences. Moreover, without dedicated designs, it remains difficult to effectively select informative and correlated representations across modalities, thereby limiting the robustness and accuracy of registration. To address these challenges, we propose a novel cross-modal registration framework composed of two key modules: the Iterative Agents Selection (IAS) module and the Reliable Agents Interaction (RAI) module. IAS enhances structural feature awareness with phase maps and employs reinforcement learning principles to efficiently select reliable agents. RAI then leverages these selected agents to guide cross-modal interactions, effectively reducing mismatches and improving overall robustness. Extensive experiments on the RGB-D Scenes v2 and 7-Scenes benchmarks demonstrate that our method consistently achieves state-of-the-art performance.
CA-I2P: Channel-Adaptive Registration Network with Global Optimal Selection
Jun 26, 2025Detection-free methods typically follow a coarse-to-fine pipeline, extracting image and point cloud features for patch-level matching and refining dense pixel-to-point correspondences. However, differences in feature channel attention between images and point clouds may lead to degraded matching results, ultimately impairing registration accuracy. Furthermore, similar structures in the scene could lead to redundant correspondences in cross-modal matching. To address these issues, we propose Channel Adaptive Adjustment Module (CAA) and Global Optimal Selection Module (GOS). CAA enhances intra-modal features and suppresses cross-modal sensitivity, while GOS replaces local selection with global optimization. Experiments on RGB-D Scenes V2 and 7-Scenes demonstrate the superiority of our method, achieving state-of-the-art performance in image-to-point cloud registration.
Knowledge-Guided Exploration in Deep Reinforcement Learning
Oct 26, 2022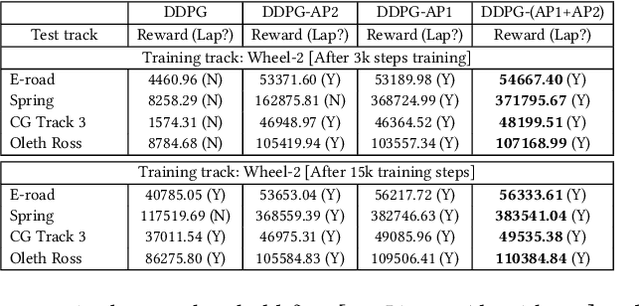
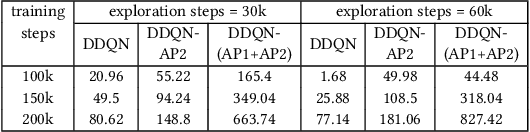

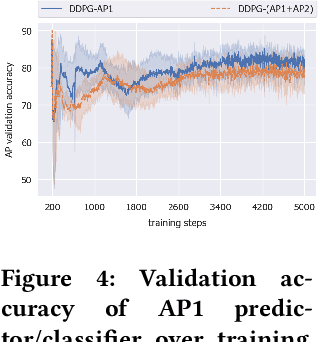
This paper proposes a new method to drastically speed up deep reinforcement learning (deep RL) training for problems that have the property of state-action permissibility (SAP). Two types of permissibility are defined under SAP. The first type says that after an action $a_t$ is performed in a state $s_t$ and the agent has reached the new state $s_{t+1}$, the agent can decide whether $a_t$ is permissible or not permissible in $s_t$. The second type says that even without performing $a_t$ in $s_t$, the agent can already decide whether $a_t$ is permissible or not in $s_t$. An action is not permissible in a state if the action can never lead to an optimal solution and thus should not be tried (over and over again). We incorporate the proposed SAP property and encode action permissibility knowledge into two state-of-the-art deep RL algorithms to guide their state-action exploration together with a virtual stopping strategy. Results show that the SAP-based guidance can markedly speed up RL training.