 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
SysBench: Can Large Language Models Follow System Messages?
Aug 20, 2024



Large Language Models (LLMs) have become instrumental across various applications, with the customization of these models to specific scenarios becoming increasingly critical. System message, a fundamental component of LLMs, is consist of carefully crafted instructions that guide the behavior of model to meet intended goals. Despite the recognized potential of system messages to optimize AI-driven solutions, there is a notable absence of a comprehensive benchmark for evaluating how well different LLMs follow these system messages. To fill this gap, we introduce SysBench, a benchmark that systematically analyzes system message following ability in terms of three challenging aspects: constraint complexity, instruction misalignment and multi-turn stability. In order to enable effective evaluation, SysBench constructs multi-turn user conversations covering various interaction relationships, based on six common types of constraints from system messages in real-world scenarios. Our dataset contains 500 system messages from various domains, each paired with 5 turns of user conversations, which have been manually formulated and checked to guarantee high quality. SysBench provides extensive evaluation across various LLMs, measuring their ability to follow specified constraints given in system messages. The results highlight both the strengths and weaknesses of existing models, offering key insights and directions for future research. The open source library SysBench is available at https://github.com/PKU-Baichuan-MLSystemLab/SysBench.
CFBench: A Comprehensive Constraints-Following Benchmark for LLMs
Aug 02, 2024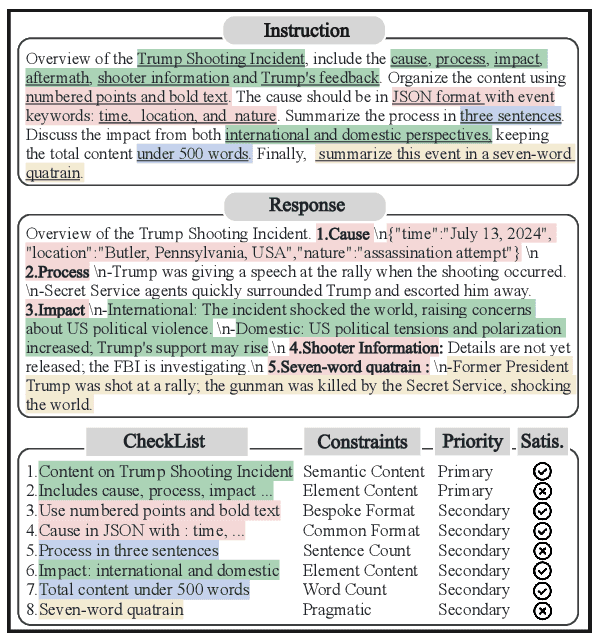


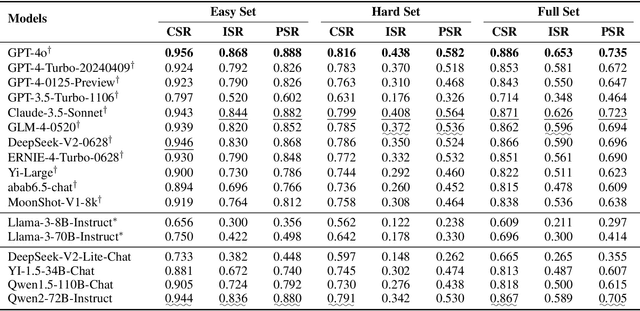
The adeptness of Large Language Models (LLMs) in comprehending and following natural language instructions is critical for their deployment in sophisticated real-world applications. Existing evaluations mainly focus on fragmented constraints or narrow scenarios, but they overlook the comprehensiveness and authenticity of constraints from the user's perspective. To bridge this gap, we propose CFBench, a large-scale Comprehensive Constraints Following Benchmark for LLMs, featuring 1,000 curated samples that cover more than 200 real-life scenarios and over 50 NLP tasks. CFBench meticulously compiles constraints from real-world instructions and constructs an innovative systematic framework for constraint types, which includes 10 primary categories and over 25 subcategories, and ensures each constraint is seamlessly integrated within the instructions. To make certain that the evaluation of LLM outputs aligns with user perceptions, we propose an advanced methodology that integrates multi-dimensional assessment criteria with requirement prioritization, covering various perspectives of constraints, instructions, and requirement fulfillment. Evaluating current leading LLMs on CFBench reveals substantial room for improvement in constraints following, and we further investigate influencing factors and enhancement strategies. The data and code are publicly available at https://github.com/PKU-Baichuan-MLSystemLab/CFBench