 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Logical Rules in Knowledge Editing: A Cherry on the Top
May 27, 2024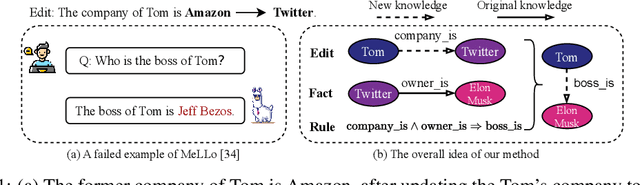
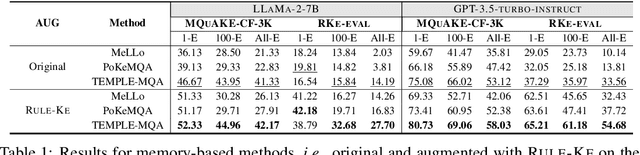

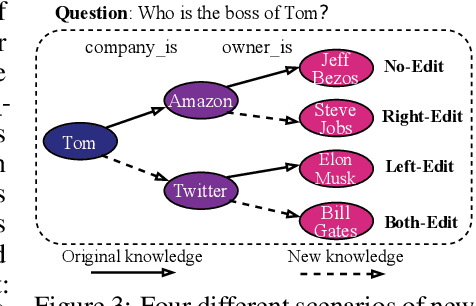
Multi-hop Question Answering (MQA) under knowledge editing (KE) is a key challenge in Large Language Models (LLMs). While best-performing solutions in this domain use a plan and solve paradigm to split a question into sub-questions followed by response generation, we claim that this approach is sub-optimal as it fails for hard to decompose questions, and it does not explicitly cater to correlated knowledge updates resulting as a consequence of knowledge edits. This has a detrimental impact on the overall consistency of the updated knowledge. To address these issues, in this paper, we propose a novel framework named RULE-KE, i.e., RULE based Knowledge Editing, which is a cherry on the top for augmenting the performance of all existing MQA methods under KE. Specifically, RULE-KE leverages rule discovery to discover a set of logical rules. Then, it uses these discovered rules to update knowledge about facts highly correlated with the edit. Experimental evaluation using existing and newly curated datasets (i.e., RKE-EVAL) shows that RULE-KE helps augment both performances of parameter-based and memory-based solutions up to 92% and 112.9%, respectively.
Multi-hop Question Answering under Temporal Knowledge Editing
Mar 30, 2024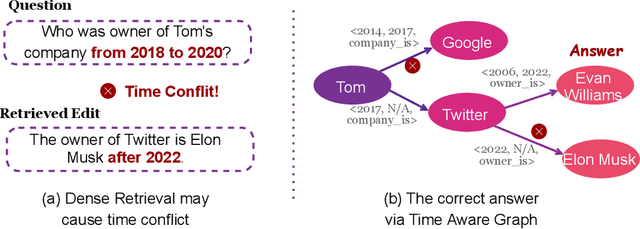
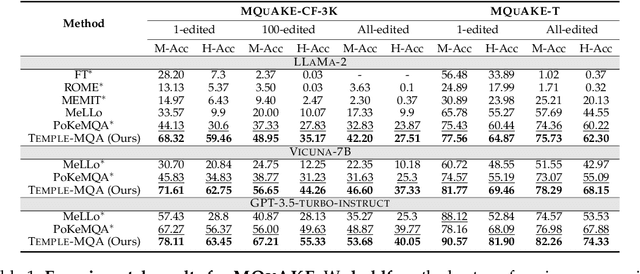
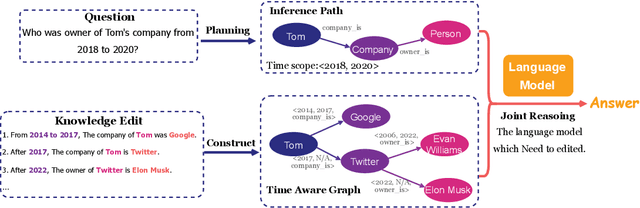
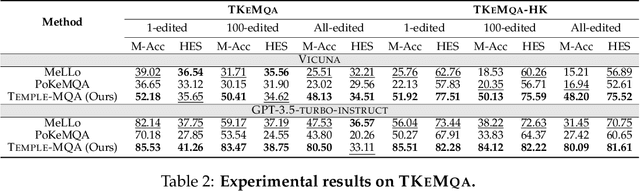
Multi-hop question answering (MQA) under knowledge editing (KE) has garnered significant attention in the era of large language models. However, existing models for MQA under KE exhibit poor performance when dealing with questions containing explicit temporal contexts. To address this limitation, we propose a novel framework, namely TEMPoral knowLEdge augmented Multi-hop Question Answering (TEMPLE-MQA). Unlike previous methods, TEMPLE-MQA first constructs a time-aware graph (TAG) to store edit knowledge in a structured manner. Then, through our proposed inference path, structural retrieval, and joint reasoning stages, TEMPLE-MQA effectively discerns temporal contexts within the question query. Experiments on benchmark datasets demonstrate that TEMPLE-MQA significantly outperforms baseline models. Additionally, we contribute a new dataset, namely TKEMQA, which serves as the inaugural benchmark tailored specifically for MQA with temporal scopes.