 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-AI Interactions in the Communication Era: Autophagy Makes Large Models Achieving Local Optima
Paper and Code
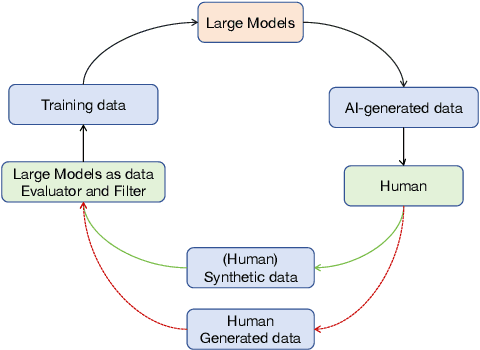
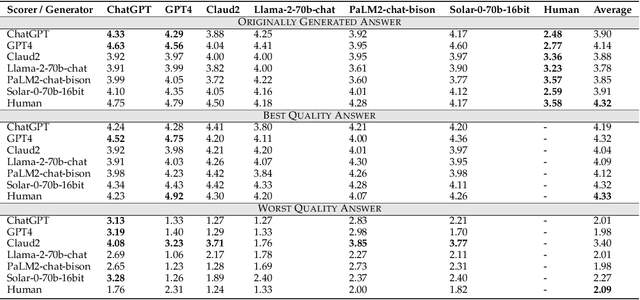
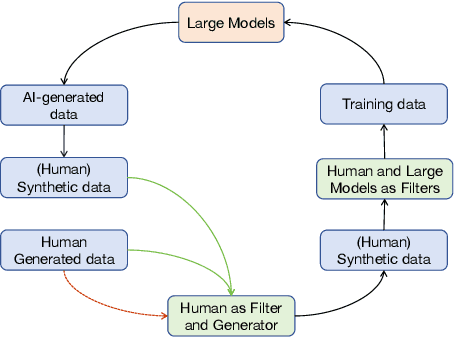
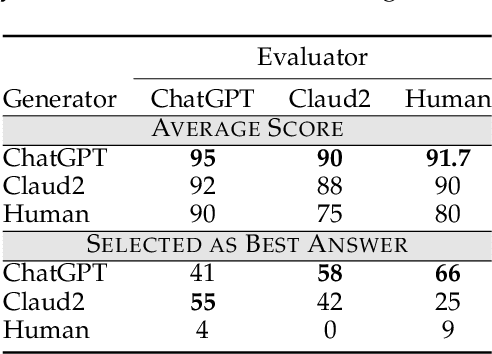
The increasing significance of large language and multimodal models in societal information processing has ignited debates on social safety and ethics. However, few studies have approached the analysis of these limitations from the comprehensive perspective of human and artificial intelligence system interactions. This study investigates biases and preferences when humans and large models are used as key links in communication. To achieve this, we design a multimodal dataset and three different experiments to evaluate generative models in their roles as producers and disseminators of information. Our main findings highlight that synthesized information is more likely to be incorporated into model training datasets and messaging than human-generated information. Additionally, large models, when acting as transmitters of information, tend to modify and lose specific content selectively. Conceptually, we present two realistic models of autophagic ("self-consumption") loops to account for the suppression of human-generated information in the exchange of information between humans and AI systems. We generalize the declining diversity of social information and the bottleneck in model performance caused by the above trends to the local optima of large models.