 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMA: Online RAG Alignment with Human Feedback
Nov 06, 2025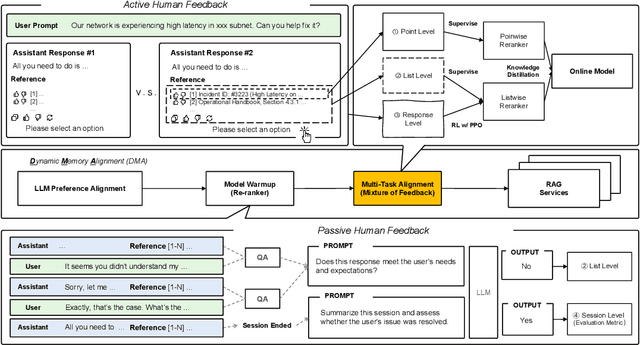

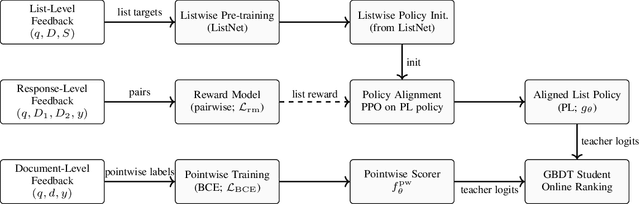
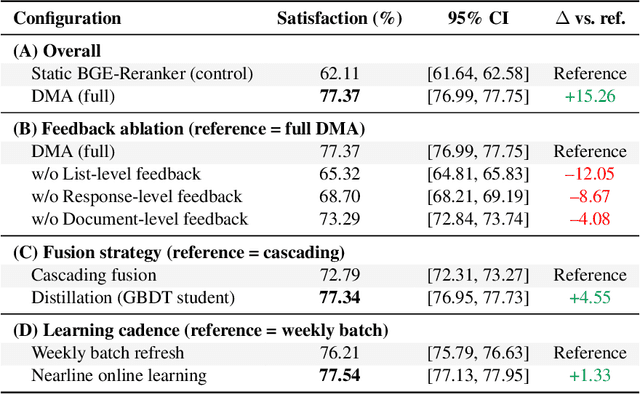
Retrieval-augmented generation (RAG) systems often rely on static retrieval, limiting adaptation to evolving intent and content drift. We introduce Dynamic Memory Alignment (DMA), an online learning framework that systematically incorporates multi-granularity human feedback to align ranking in interactive settings. DMA organizes document-, list-, and response-level signals into a coherent learning pipeline: supervised training for pointwise and listwise rankers, policy optimization driven by response-level preferences, and knowledge distillation into a lightweight scorer for low-latency serving. Throughout this paper, memory refers to the model's working memory, which is the entire context visible to the LLM for In-Context Learning. We adopt a dual-track evaluation protocol mirroring deployment: (i) large-scale online A/B ablations to isolate the utility of each feedback source, and (ii) few-shot offline tests on knowledge-intensive benchmarks. Online, a multi-month industrial deployment further shows substantial improvements in human engagement. Offline, DMA preserves competitive foundational retrieval while yielding notable gains on conversational QA (TriviaQA, HotpotQA). Taken together, these results position DMA as a principled approach to feedback-driven, real-time adaptation in RAG without sacrificing baseline capability.
ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents
Aug 19, 2025We introduce ComputerRL, a framework for autonomous desktop intelligence that enables agents to operate complex digital workspaces skillfully. ComputerRL features the API-GUI paradigm, which unifies programmatic API calls and direct GUI interaction to address the inherent mismatch between machine agents and human-centric desktop environments. Scaling end-to-end RL training is crucial for improvement and generalization across diverse desktop tasks, yet remains challenging due to environmental inefficiency and instability in extended training. To support scalable and robust training, we develop a distributed RL infrastructure capable of orchestrating thousands of parallel virtual desktop environments to accelerate large-scale online RL. Furthermore, we propose Entropulse, a training strategy that alternates reinforcement learning with supervised fine-tuning, effectively mitigating entropy collapse during extended training runs. We employ ComputerRL on open models GLM-4-9B-0414 and Qwen2.5-14B, and evaluate them on the OSWorld benchmark. The AutoGLM-OS-9B based on GLM-4-9B-0414 achieves a new state-of-the-art accuracy of 48.1%, demonstrating significant improvements for general agents in desktop automation. The algorithm and framework are adopted in building AutoGLM (Liu et al., 2024a)
Pistis-RAG: A Scalable Cascading Framework Towards Trustworthy Retrieval-Augmented Generation
Jun 21, 2024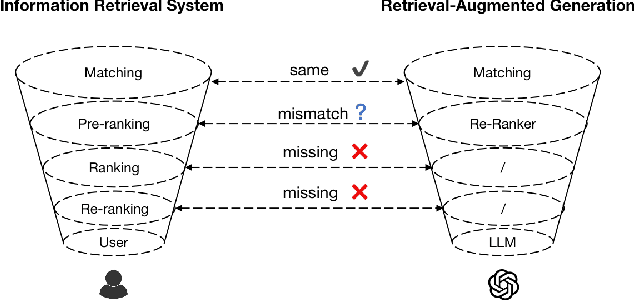



In Greek mythology, Pistis symbolized good faith, trust, and reliability, echoing the core principles of RAG in LLM systems. Pistis-RAG, a scalable multi-stage framework, effectively addresses the challenges of large-scale retrieval-augmented generation (RAG). Each stage plays a distinct role: matching refines the search space, pre-ranking prioritizes semantically relevant documents, and ranking aligns with the large language model's (LLM) preferences. The reasoning and aggregating stage supports the implementation of complex chain-of-thought (CoT) methods within this cascading structure. We argue that the lack of strong alignment between LLMs and the external knowledge ranking methods used in RAG tasks is relevant to the reliance on the model-centric paradigm in RAG frameworks. A content-centric approach would prioritize seamless integration between the LLMs and external information sources, optimizing the content transformation process for each specific task. Critically, our ranking stage deviates from traditional RAG approaches by recognizing that semantic relevance alone may not directly translate to improved generation. This is due to the sensitivity of the few-shot prompt order, as highlighted in prior work \cite{lu2021fantastically}. Current RAG frameworks fail to account for this crucial factor. We introduce a novel ranking stage specifically designed for RAG systems. It adheres to information retrieval principles while considering the unique business scenario captured by LLM preferences and user feedback. Our approach integrates in-context learning (ICL) methods and reasoning steps to incorporate user feedback, ensuring efficient alignment. Experiments on the MMLU benchmark demonstrate a 9.3\% performance improvement. The model and code will be open-sourced on GitHub. Experiments on real-world, large-scale data validate our framework's scalability.
An Empirical Study of NetOps Capability of Pre-Trained Large Language Models
Sep 19, 2023



Nowadays, the versatile capabilities of Pre-trained Large Language Models (LLMs) have attracted much attention from the industry. However, some vertical domains are more interested in the in-domain capabilities of LLMs. For the Networks domain, we present NetEval, an evaluation set for measuring the comprehensive capabilities of LLMs in Network Operations (NetOps). NetEval is designed for evaluating the commonsense knowledge and inference ability in NetOps in a multi-lingual context. NetEval consists of 5,732 questions about NetOps, covering five different sub-domains of NetOps. With NetEval, we systematically evaluate the NetOps capability of 26 publicly available LLMs. The results show that only GPT-4 can achieve a performance competitive to humans. However, some open models like LLaMA 2 demonstrate significant potential.