 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMA: Online RAG Alignment with Human Feedback
Nov 06, 2025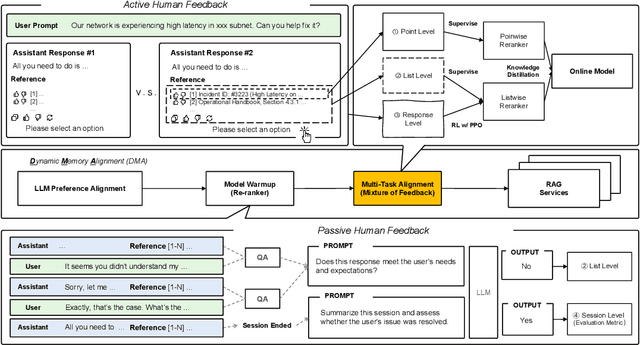

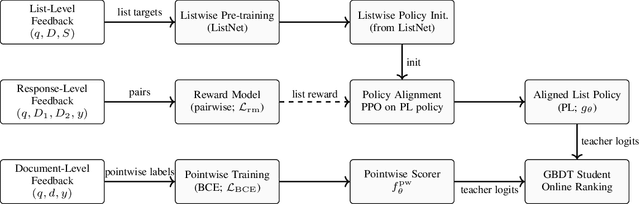
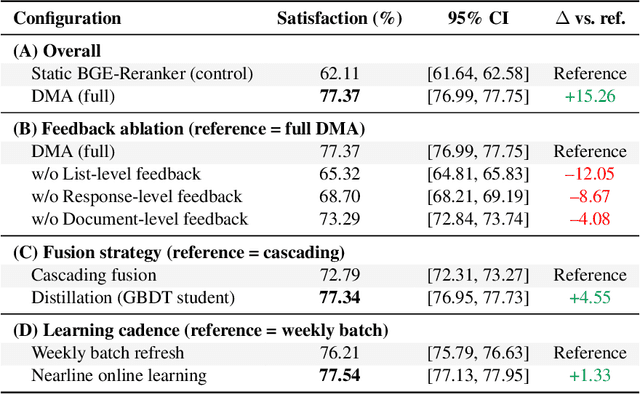
Retrieval-augmented generation (RAG) systems often rely on static retrieval, limiting adaptation to evolving intent and content drift. We introduce Dynamic Memory Alignment (DMA), an online learning framework that systematically incorporates multi-granularity human feedback to align ranking in interactive settings. DMA organizes document-, list-, and response-level signals into a coherent learning pipeline: supervised training for pointwise and listwise rankers, policy optimization driven by response-level preferences, and knowledge distillation into a lightweight scorer for low-latency serving. Throughout this paper, memory refers to the model's working memory, which is the entire context visible to the LLM for In-Context Learning. We adopt a dual-track evaluation protocol mirroring deployment: (i) large-scale online A/B ablations to isolate the utility of each feedback source, and (ii) few-shot offline tests on knowledge-intensive benchmarks. Online, a multi-month industrial deployment further shows substantial improvements in human engagement. Offline, DMA preserves competitive foundational retrieval while yielding notable gains on conversational QA (TriviaQA, HotpotQA). Taken together, these results position DMA as a principled approach to feedback-driven, real-time adaptation in RAG without sacrificing baseline capability.
Pistis-RAG: A Scalable Cascading Framework Towards Trustworthy Retrieval-Augmented Generation
Jun 21, 2024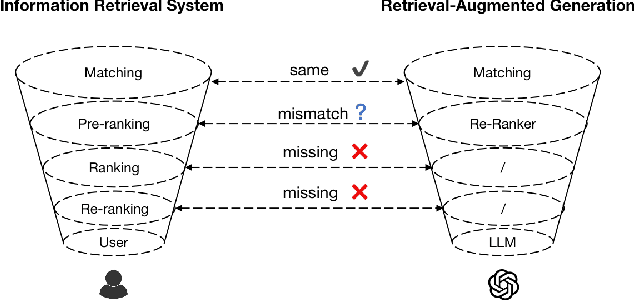



In Greek mythology, Pistis symbolized good faith, trust, and reliability, echoing the core principles of RAG in LLM systems. Pistis-RAG, a scalable multi-stage framework, effectively addresses the challenges of large-scale retrieval-augmented generation (RAG). Each stage plays a distinct role: matching refines the search space, pre-ranking prioritizes semantically relevant documents, and ranking aligns with the large language model's (LLM) preferences. The reasoning and aggregating stage supports the implementation of complex chain-of-thought (CoT) methods within this cascading structure. We argue that the lack of strong alignment between LLMs and the external knowledge ranking methods used in RAG tasks is relevant to the reliance on the model-centric paradigm in RAG frameworks. A content-centric approach would prioritize seamless integration between the LLMs and external information sources, optimizing the content transformation process for each specific task. Critically, our ranking stage deviates from traditional RAG approaches by recognizing that semantic relevance alone may not directly translate to improved generation. This is due to the sensitivity of the few-shot prompt order, as highlighted in prior work \cite{lu2021fantastically}. Current RAG frameworks fail to account for this crucial factor. We introduce a novel ranking stage specifically designed for RAG systems. It adheres to information retrieval principles while considering the unique business scenario captured by LLM preferences and user feedback. Our approach integrates in-context learning (ICL) methods and reasoning steps to incorporate user feedback, ensuring efficient alignment. Experiments on the MMLU benchmark demonstrate a 9.3\% performance improvement. The model and code will be open-sourced on GitHub. Experiments on real-world, large-scale data validate our framework's scalability.
Learning to Simulate Unseen Physical Systems with Graph Neural Networks
Jan 28, 2022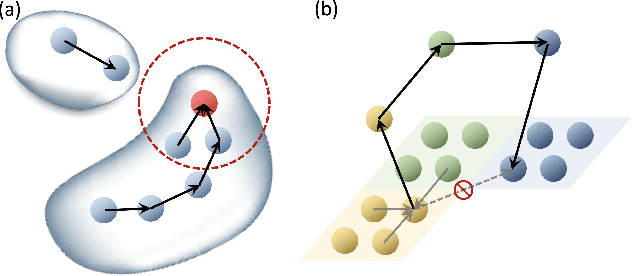
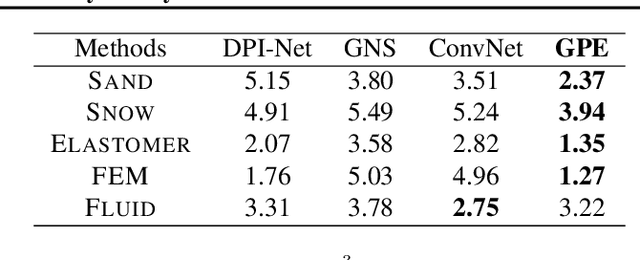
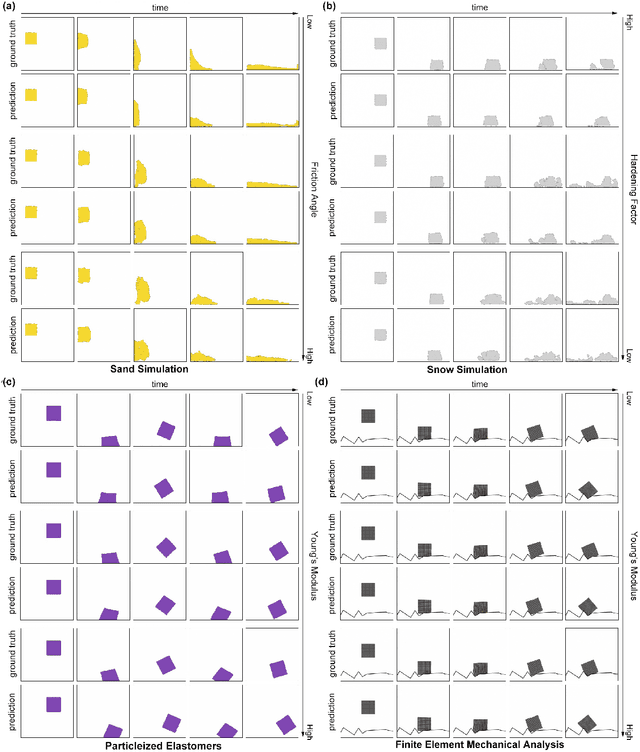

Simulation of the dynamics of physical systems is essential to the development of both science and engineering. Recently there is an increasing interest in learning to simulate the dynamics of physical systems using neural networks. However, existing approaches fail to generalize to physical substances not in the training set, such as liquids with different viscosities or elastomers with different elasticities. Here we present a machine learning method embedded with physical priors and material parameters, which we term as "Graph-based Physics Engine" (GPE), to efficiently model the physical dynamics of different substances in a wide variety of scenarios. We demonstrate that GPE can generalize to materials with different properties not seen in the training set and perform well from single-step predictions to multi-step roll-out simulations. In addition, introducing the law of momentum conservation in the model significantly improves the efficiency and stability of learning, allowing convergence to better models with fewer training steps.
Aerial hyperspectral imagery and deep neural networks for high-throughput yield phenotyping in wheat
Jun 23, 2019



Crop production needs to increase in a sustainable manner to meet the growing global demand for food. To identify crop varieties with high yield potential, plant scientists and breeders evaluate the performance of hundreds of lines in multiple locations over several years. To facilitate the process of selecting advanced varieties, an automated framework was developed in this study. A hyperspectral camera was mounted on an unmanned aerial vehicle to collect aerial imagery with high spatial and spectral resolution. Aerial images were captured in two consecutive growing seasons from three experimental yield fields composed of hundreds experimental plots (1x2.4 meter), each contained a single wheat line. The grain of more than thousand wheat plots was harvested by a combine, weighed, and recorded as the ground truth data. To leverage the high spatial resolution and investigate the yield variation within the plots, images of plots were divided into sub-plots by integrating image processing techniques and spectral mixture analysis with the expert domain knowledge. Afterwards, the sub-plot dataset was divided into train, validation, and test sets using stratified sampling. Subsequent to extracting features from each sub-plot, deep neural networks were trained for yield estimation. The coefficient of determination for predicting the yield of the test dataset at sub-plot scale was 0.79 with root mean square error of 5.90 grams. In addition to providing insights into yield variation at sub-plot scale, the proposed framework can facilitate the process of high-throughput yield phenotyping as a valuable decision support tool. It offers the possibility of (i) remote visual inspection of the plots, (ii) studying the effect of crop density on yield, and (iii) optimizing plot size to investigate more lines in a dedicated field each year.