 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$f$-PO: Generalizing Preference Optimization with $f$-divergence Minimization
Paper and Code
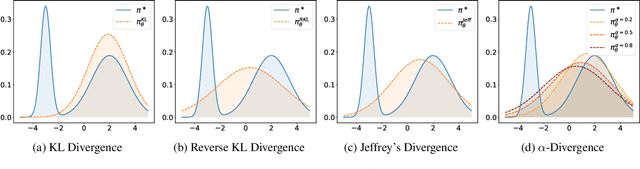

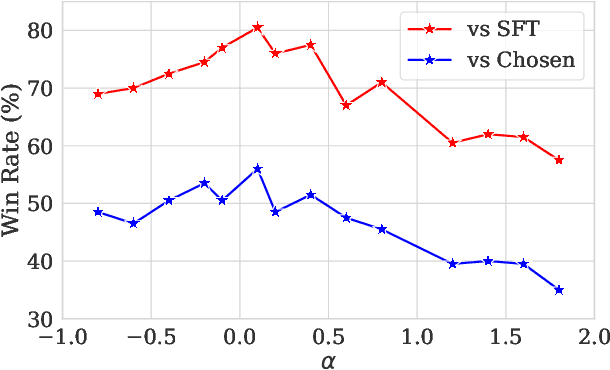

Preference optimization has made significant progress recently, with numerous methods developed to align language models with human preferences. This paper introduces $f$-divergence Preference Optimization ($f$-PO), a novel framework that generalizes and extends existing approaches. $f$-PO minimizes $f$-divergences between the optimized policy and the optimal policy, encompassing a broad family of alignment methods using various divergences. Our approach unifies previous algorithms like DPO and EXO, while offering new variants through different choices of $f$-divergences. We provide theoretical analysis of $f$-PO's properties and conduct extensive experiments on state-of-the-art language models using benchmark datasets. Results demonstrate $f$-PO's effectiveness across various tasks, achieving superior performance compared to existing methods on popular benchmarks such as AlpacaEval 2, Arena-Hard, and MT-Bench. Additionally, we present ablation studies exploring the impact of different $f$-divergences, offering insights into the trade-offs between regularization and performance in offline preference optimization. Our work contributes both practical algorithms and theoretical understanding to the field of language model alignment. Code is available at https://github.com/MinkaiXu/fPO.