 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexture Transform Attention for Realistic Image Inpainting
Paper and Code
Dec 08, 2020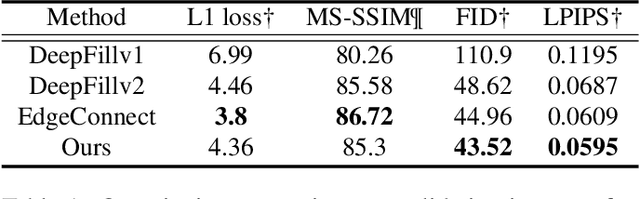

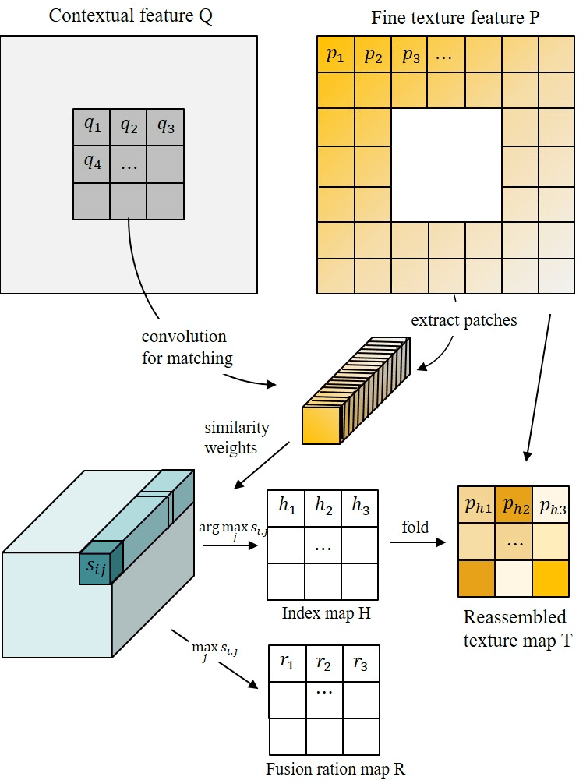

Over the last few years, the performance of inpainting to fill missing regions has shown significant improvements by using deep neural networks. Most of inpainting work create a visually plausible structure and texture, however, due to them often generating a blurry result, final outcomes appear unrealistic and make feel heterogeneity. In order to solve this problem, the existing methods have used a patch based solution with deep neural network, however, these methods also cannot transfer the texture properly. Motivated by these observation, we propose a patch based method. Texture Transform Attention network(TTA-Net) that better produces the missing region inpainting with fine details. The task is a single refinement network and takes the form of U-Net architecture that transfers fine texture features of encoder to coarse semantic features of decoder through skip-connection. Texture Transform Attention is used to create a new reassembled texture map using fine textures and coarse semantics that can efficiently transfer texture information as a result. To stabilize training process, we use a VGG feature layer of ground truth and patch discriminator. We evaluate our model end-to-end with the publicly available datasets CelebA-HQ and Places2 and demonstrate that images of higher quality can be obtained to the existing state-of-the-art approaches.