 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021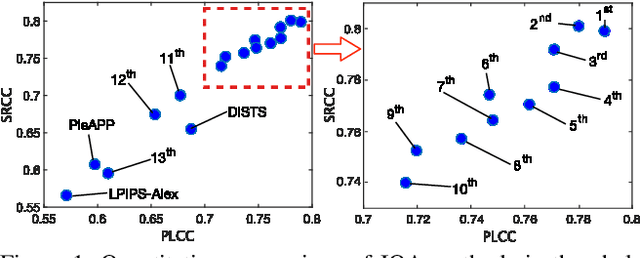
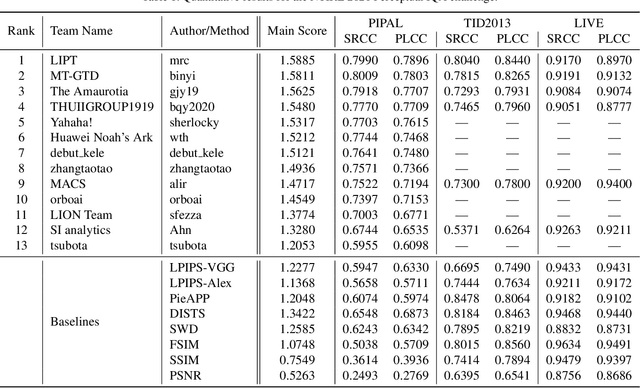

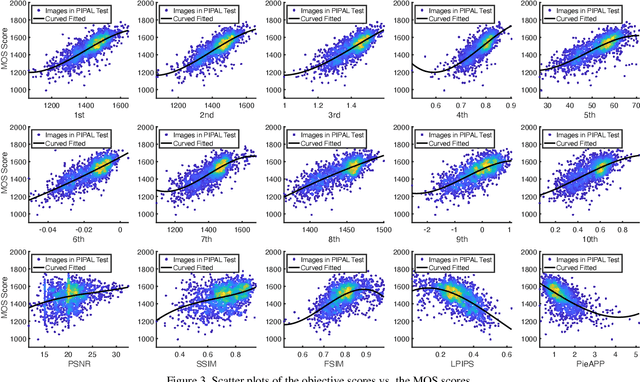
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
Perceptual Image Quality Assessment with Transformers
May 05, 2021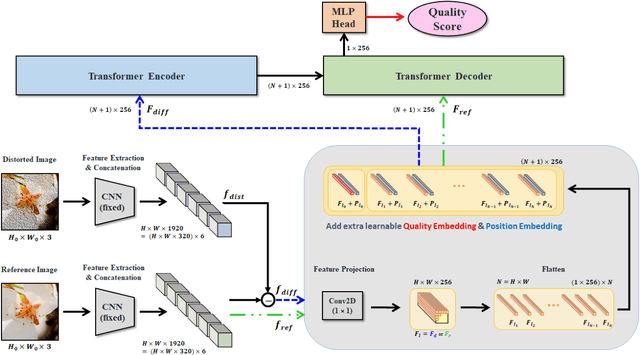

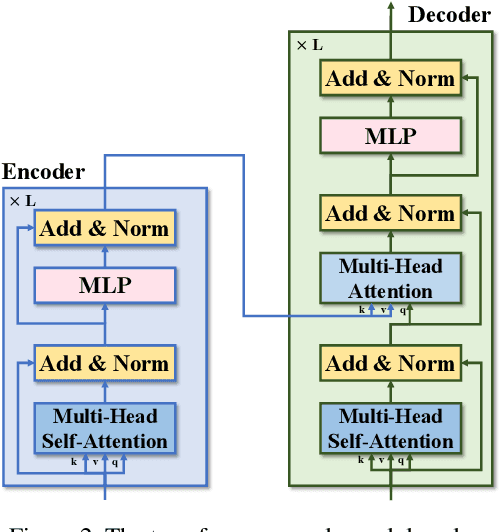
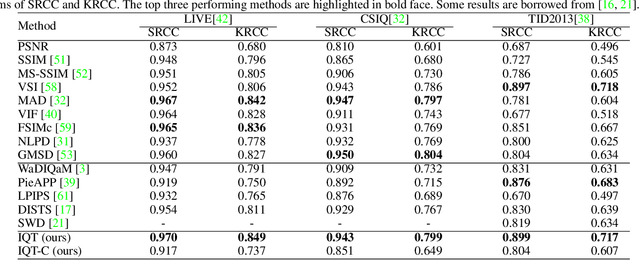
In this paper, we propose an image quality transformer (IQT) that successfully applies a transformer architecture to a perceptual full-reference image quality assessment (IQA) task. Perceptual representation becomes more important in image quality assessment. In this context, we extract the perceptual feature representations from each of input images using a convolutional neural network (CNN) backbone. The extracted feature maps are fed into the transformer encoder and decoder in order to compare a reference and distorted images. Following an approach of the transformer-based vision models, we use extra learnable quality embedding and position embedding. The output of the transformer is passed to a prediction head in order to predict a final quality score. The experimental results show that our proposed model has an outstanding performance for the standard IQA datasets. For a large-scale IQA dataset containing output images of generative model, our model also shows the promising results. The proposed IQT was ranked first among 13 participants in the NTIRE 2021 perceptual image quality assessment challenge. Our work will be an opportunity to further expand the approach for the perceptual IQA task.
Texture Transform Attention for Realistic Image Inpainting
Dec 08, 2020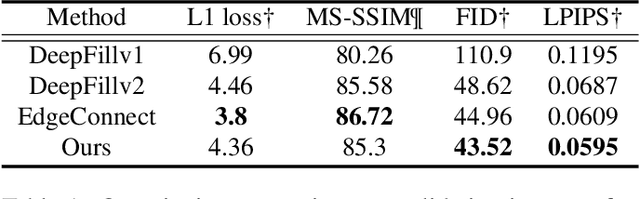

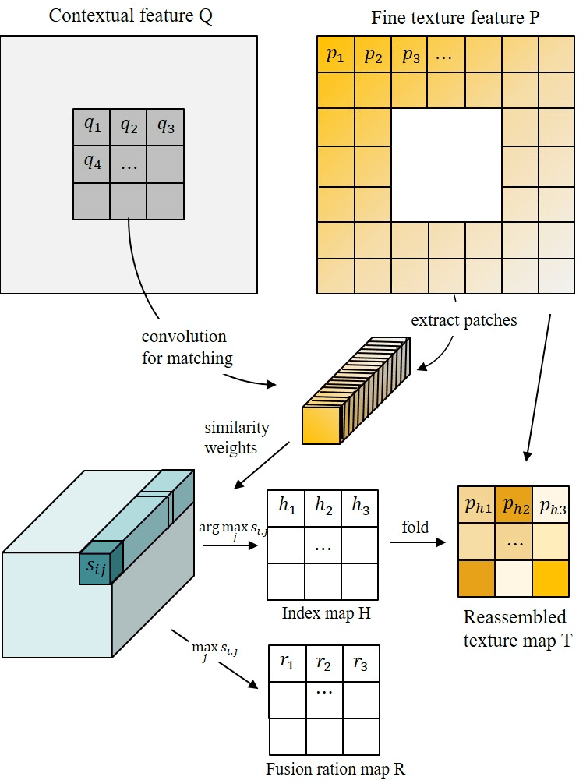

Over the last few years, the performance of inpainting to fill missing regions has shown significant improvements by using deep neural networks. Most of inpainting work create a visually plausible structure and texture, however, due to them often generating a blurry result, final outcomes appear unrealistic and make feel heterogeneity. In order to solve this problem, the existing methods have used a patch based solution with deep neural network, however, these methods also cannot transfer the texture properly. Motivated by these observation, we propose a patch based method. Texture Transform Attention network(TTA-Net) that better produces the missing region inpainting with fine details. The task is a single refinement network and takes the form of U-Net architecture that transfers fine texture features of encoder to coarse semantic features of decoder through skip-connection. Texture Transform Attention is used to create a new reassembled texture map using fine textures and coarse semantics that can efficiently transfer texture information as a result. To stabilize training process, we use a VGG feature layer of ground truth and patch discriminator. We evaluate our model end-to-end with the publicly available datasets CelebA-HQ and Places2 and demonstrate that images of higher quality can be obtained to the existing state-of-the-art approaches.
NTIRE 2020 Challenge on Image Demoireing: Methods and Results
May 06, 2020



This paper reviews the Challenge on Image Demoireing that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2020. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. The challenge was divided into two tracks. Track 1 targeted the single image demoireing problem, which seeks to remove moire patterns from a single image. Track 2 focused on the burst demoireing problem, where a set of degraded moire images of the same scene were provided as input, with the goal of producing a single demoired image as output. The methods were ranked in terms of their fidelity, measured using the peak signal-to-noise ratio (PSNR) between the ground truth clean images and the restored images produced by the participants' methods. The tracks had 142 and 99 registered participants, respectively, with a total of 14 and 6 submissions in the final testing stage. The entries span the current state-of-the-art in image and burst image demoireing problems.