 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvTransformer: A Convolutional Transformer Network for Video Frame Synthesis
Nov 20, 2020
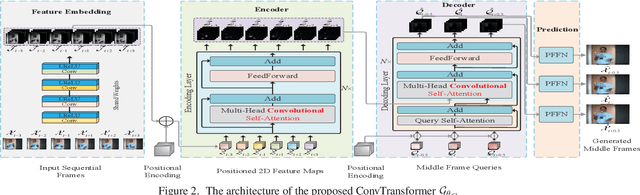
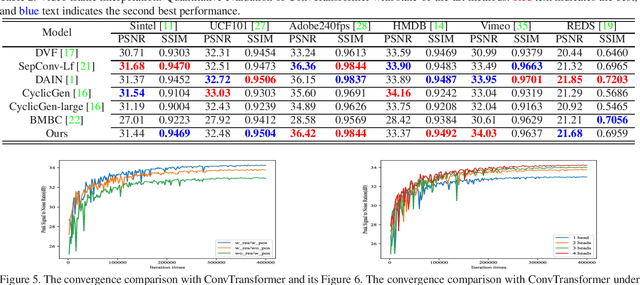
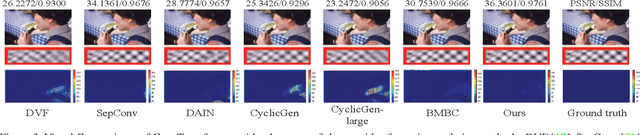
Deep Convolutional Neural Networks (CNNs) are powerful models that have achieved excellent performance on difficult computer vision tasks. Although CNNS perform well whenever large labeled training samples are available, they work badly on video frame synthesis due to objects deforming and moving, scene lighting changes, and cameras moving in video sequence. In this paper, we present a novel and general end-to-end architecture, called convolutional Transformer or ConvTransformer, for video frame sequence learning and video frame synthesis. The core ingredient of ConvTransformer is the proposed attention layer, i.e., multi-head convolutional self-attention, that learns the sequential dependence of video sequence. Our method ConvTransformer uses an encoder, built upon multi-head convolutional self-attention layers, to map the input sequence to a feature map sequence, and then another deep networks, incorporating multi-head convolutional self-attention layers, decode the target synthesized frames from the feature maps sequence. Experiments on video future frame extrapolation task show ConvTransformer to be superior in quality while being more parallelizable to recent approaches built upon convoltuional LSTM (ConvLSTM). To the best of our knowledge, this is the first time that ConvTransformer architecture is proposed and applied to video frame synthesis.