 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDS-Fusion: Artistic Typography via Discriminated and Stylized Diffusion
Paper and Code
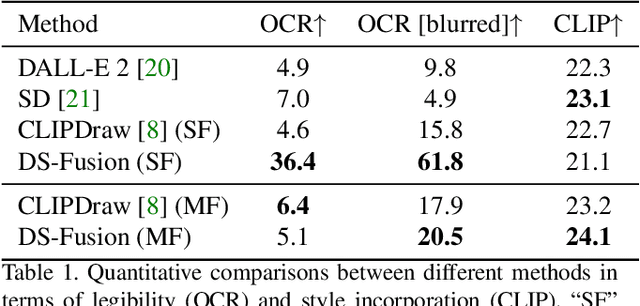
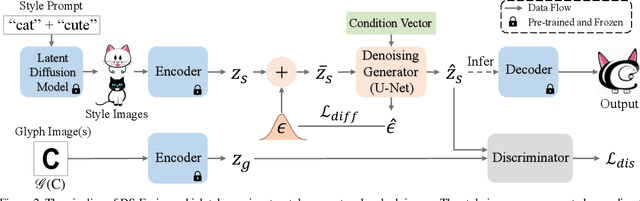
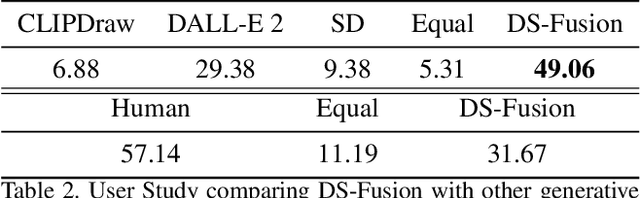
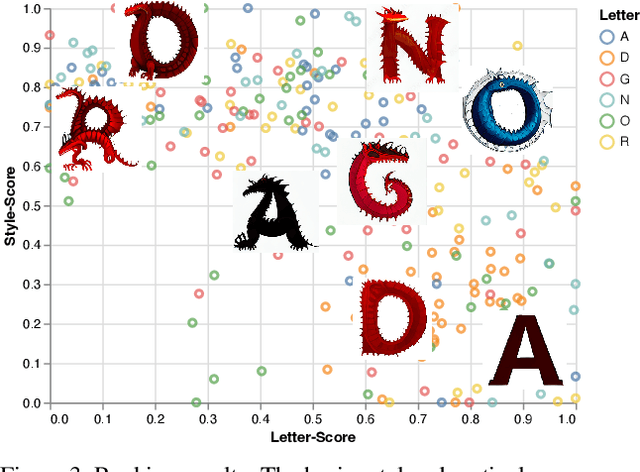
We introduce a novel method to automatically generate an artistic typography by stylizing one or more letter fonts to visually convey the semantics of an input word, while ensuring that the output remains readable. To address an assortment of challenges with our task at hand including conflicting goals (artistic stylization vs. legibility), lack of ground truth, and immense search space, our approach utilizes large language models to bridge texts and visual images for stylization and build an unsupervised generative model with a diffusion model backbone. Specifically, we employ the denoising generator in Latent Diffusion Model (LDM), with the key addition of a CNN-based discriminator to adapt the input style onto the input text. The discriminator uses rasterized images of a given letter/word font as real samples and output of the denoising generator as fake samples. Our model is coined DS-Fusion for discriminated and stylized diffusion. We showcase the quality and versatility of our method through numerous examples, qualitative and quantitative evaluation, as well as ablation studies. User studies comparing to strong baselines including CLIPDraw and DALL-E 2, as well as artist-crafted typographies, demonstrate strong performance of DS-Fusion.