 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Reasoning Abilities of ChatGPT in the Context of Claim Verification
Paper and Code
Feb 16, 2024
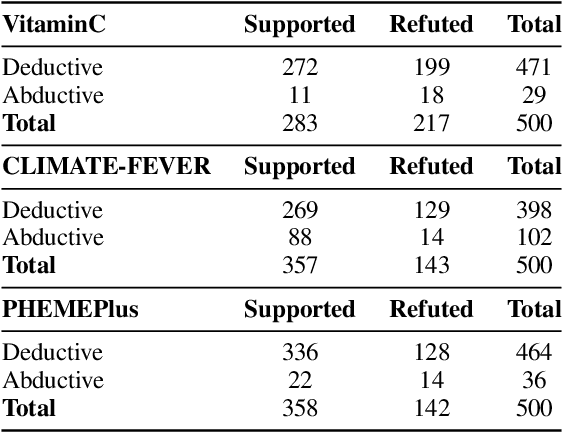
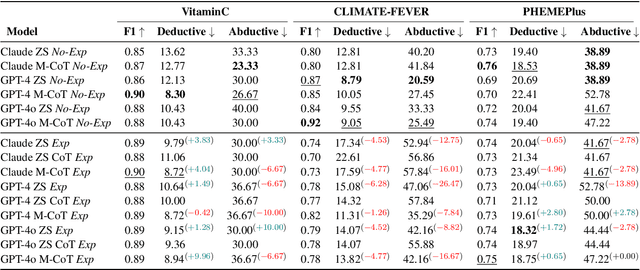
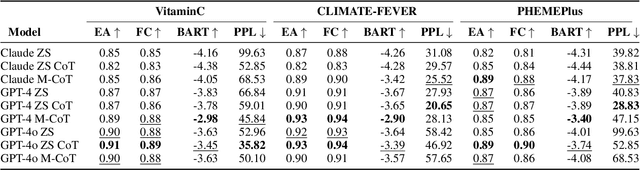
The reasoning capabilities of LLMs are currently hotly debated. We examine the issue from the perspective of claim/rumour verification. We propose the first logical reasoning framework designed to break down any claim or rumor paired with evidence into the atomic reasoning steps necessary for verification. Based on our framework, we curate two annotated collections of such claim/evidence pairs: a synthetic dataset from Wikipedia and a real-world set stemming from rumours circulating on Twitter. We use them to evaluate the reasoning capabilities of GPT-3.5-Turbo and GPT-4 (hereinafter referred to as ChatGPT) within the context of our framework, providing a thorough analysis. Our results show that ChatGPT struggles in abductive reasoning, although this can be somewhat mitigated by using manual Chain of Thought (CoT) as opposed to Zero Shot (ZS) and ZS CoT approaches. Our study contributes to the growing body of research suggesting that ChatGPT's reasoning processes are unlikely to mirror human-like reasoning, and that LLMs need to be more rigorously evaluated in order to distinguish between hype and actual capabilities, especially in high stake real-world tasks such as claim verification.