 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Alignment Bottleneck in Decomposition-Based Claim Verification
Feb 11, 2026Structured claim decomposition is often proposed as a solution for verifying complex, multi-faceted claims, yet empirical results have been inconsistent. We argue that these inconsistencies stem from two overlooked bottlenecks: evidence alignment and sub-claim error profiles. To better understand these factors, we introduce a new dataset of real-world complex claims, featuring temporally bounded evidence and human-annotated sub-claim evidence spans. We evaluate decomposition under two evidence alignment setups: Sub-claim Aligned Evidence (SAE) and Repeated Claim-level Evidence (SRE). Our results reveal that decomposition brings significant performance improvement only when evidence is granular and strictly aligned. By contrast, standard setups that rely on repeated claim-level evidence (SRE) fail to improve and often degrade performance as shown across different datasets and domains (PHEMEPlus, MMM-Fact, COVID-Fact). Furthermore, we demonstrate that in the presence of noisy sub-claim labels, the nature of the error ends up determining downstream robustness. We find that conservative "abstention" significantly reduces error propagation compared to aggressive but incorrect predictions. These findings suggest that future claim decomposition frameworks must prioritize precise evidence synthesis and calibrate the label bias of sub-claim verification models.
Assessing the Reasoning Abilities of ChatGPT in the Context of Claim Verification
Feb 16, 2024
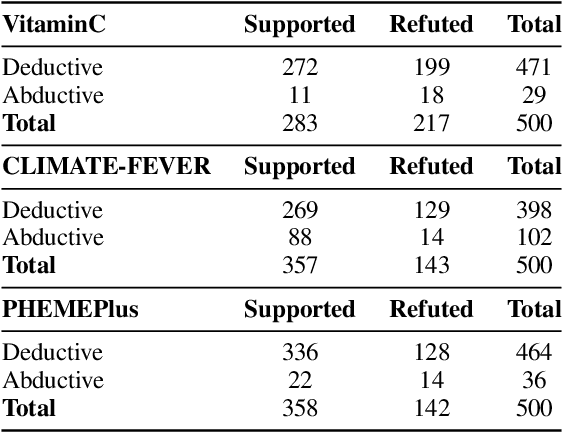
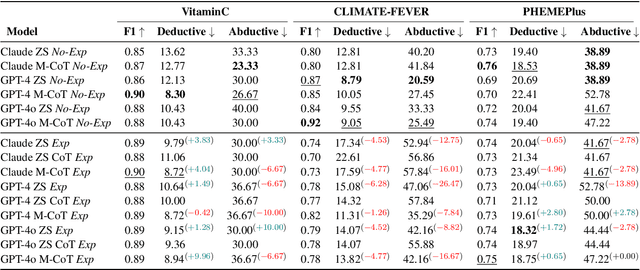
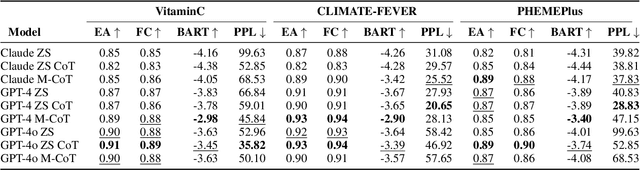
The reasoning capabilities of LLMs are currently hotly debated. We examine the issue from the perspective of claim/rumour verification. We propose the first logical reasoning framework designed to break down any claim or rumor paired with evidence into the atomic reasoning steps necessary for verification. Based on our framework, we curate two annotated collections of such claim/evidence pairs: a synthetic dataset from Wikipedia and a real-world set stemming from rumours circulating on Twitter. We use them to evaluate the reasoning capabilities of GPT-3.5-Turbo and GPT-4 (hereinafter referred to as ChatGPT) within the context of our framework, providing a thorough analysis. Our results show that ChatGPT struggles in abductive reasoning, although this can be somewhat mitigated by using manual Chain of Thought (CoT) as opposed to Zero Shot (ZS) and ZS CoT approaches. Our study contributes to the growing body of research suggesting that ChatGPT's reasoning processes are unlikely to mirror human-like reasoning, and that LLMs need to be more rigorously evaluated in order to distinguish between hype and actual capabilities, especially in high stake real-world tasks such as claim verification.
Does Transliteration Help Multilingual Language Modeling?
Jan 29, 2022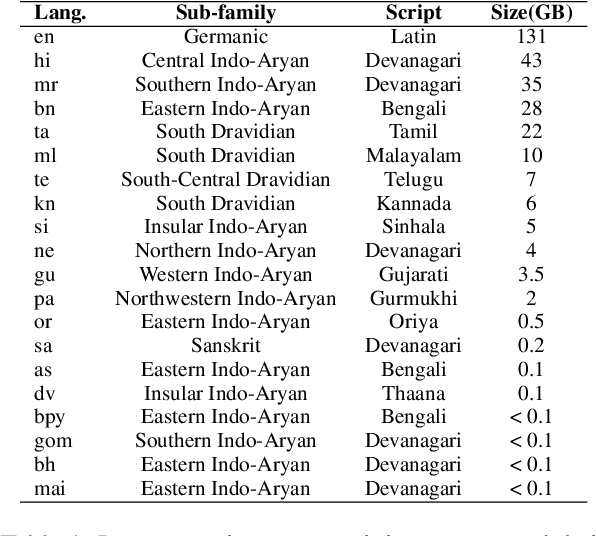
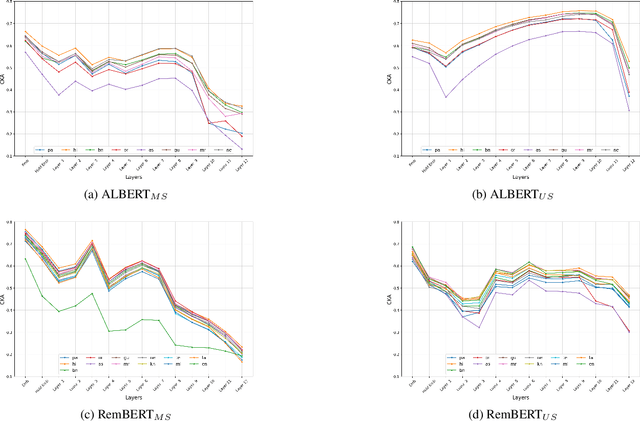
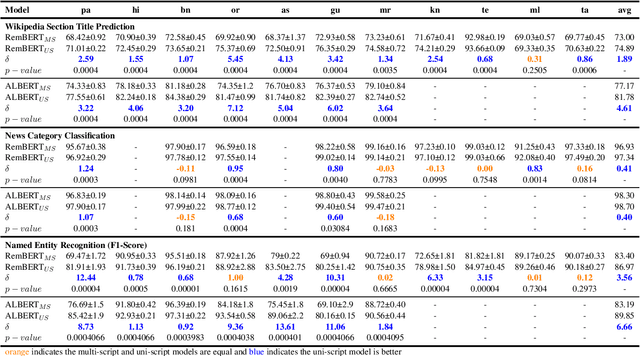
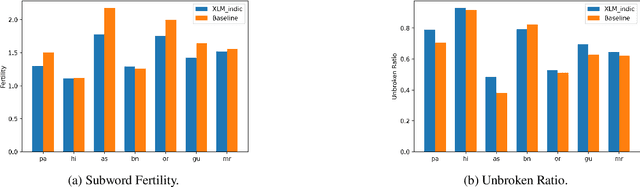
As there is a scarcity of large representative corpora for most languages, it is important for Multilingual Language Models (MLLM) to extract the most out of existing corpora. In this regard, script diversity presents a challenge to MLLMs by reducing lexical overlap among closely related languages. Therefore, transliterating closely related languages that use different writing scripts to a common script may improve the downstream task performance of MLLMs. In this paper, we pretrain two ALBERT models to empirically measure the effect of transliteration on MLLMs. We specifically focus on the Indo-Aryan language family, which has the highest script diversity in the world. Afterward, we evaluate our models on the IndicGLUE benchmark. We perform Mann-Whitney U test to rigorously verify whether the effect of transliteration is significant or not. We find that transliteration benefits the low-resource languages without negatively affecting the comparatively high-resource languages. We also measure the cross-lingual representation similarity (CLRS) of the models using centered kernel alignment (CKA) on parallel sentences of eight languages from the FLORES-101 dataset. We find that the hidden representations of the transliteration-based model have higher and more stable CLRS scores. Our code is available at Github (github.com/ibraheem-moosa/XLM-Indic) and Hugging Face Hub (huggingface.co/ibraheemmoosa/xlmindic-base-multiscript and huggingface.co/ibraheemmoosa/xlmindic-base-uniscript).