 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Transliteration Help Multilingual Language Modeling?
Paper and Code
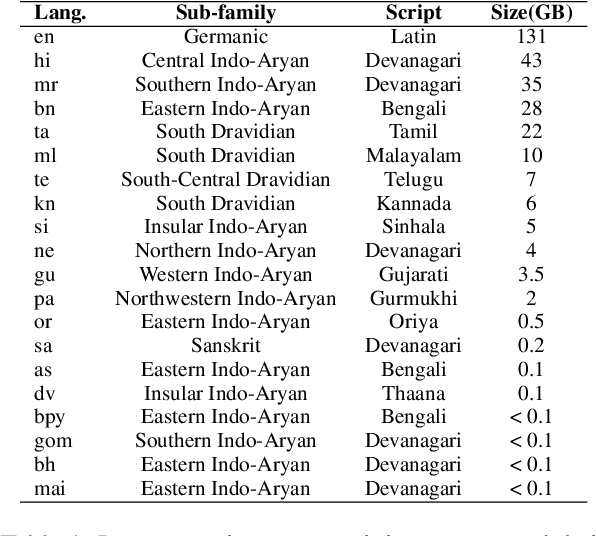
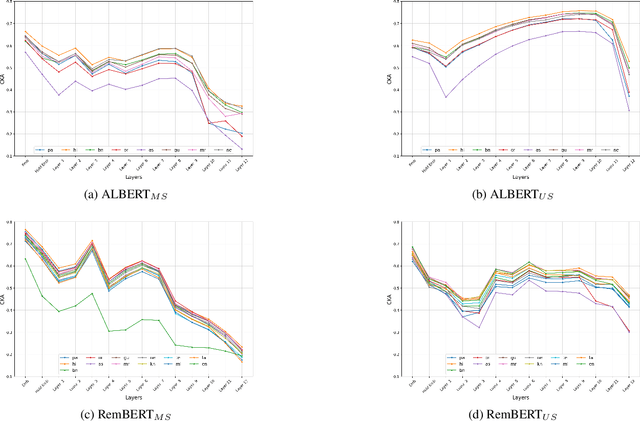
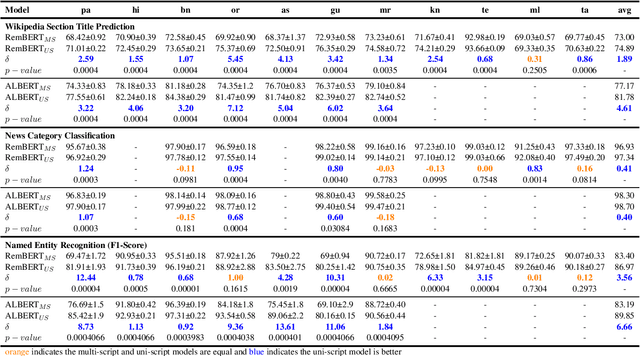
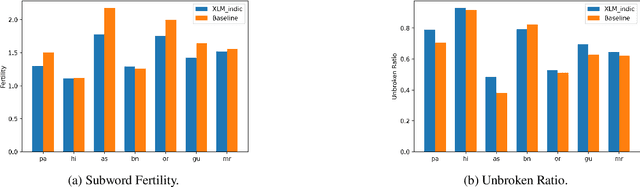
As there is a scarcity of large representative corpora for most languages, it is important for Multilingual Language Models (MLLM) to extract the most out of existing corpora. In this regard, script diversity presents a challenge to MLLMs by reducing lexical overlap among closely related languages. Therefore, transliterating closely related languages that use different writing scripts to a common script may improve the downstream task performance of MLLMs. In this paper, we pretrain two ALBERT models to empirically measure the effect of transliteration on MLLMs. We specifically focus on the Indo-Aryan language family, which has the highest script diversity in the world. Afterward, we evaluate our models on the IndicGLUE benchmark. We perform Mann-Whitney U test to rigorously verify whether the effect of transliteration is significant or not. We find that transliteration benefits the low-resource languages without negatively affecting the comparatively high-resource languages. We also measure the cross-lingual representation similarity (CLRS) of the models using centered kernel alignment (CKA) on parallel sentences of eight languages from the FLORES-101 dataset. We find that the hidden representations of the transliteration-based model have higher and more stable CLRS scores. Our code is available at Github (github.com/ibraheem-moosa/XLM-Indic) and Hugging Face Hub (huggingface.co/ibraheemmoosa/xlmindic-base-multiscript and huggingface.co/ibraheemmoosa/xlmindic-base-uniscript).