 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurobiber: Fast and Interpretable Stylistic Feature Extraction
Feb 25, 2025



Linguistic style is pivotal for understanding how texts convey meaning and fulfill communicative purposes, yet extracting detailed stylistic features at scale remains challenging. We present Neurobiber, a transformer-based system for fast, interpretable style profiling built on Biber's Multidimensional Analysis (MDA). Neurobiber predicts 96 Biber-style features from our open-source BiberPlus library (a Python toolkit that computes stylistic features and provides integrated analytics, e.g., PCA and factor analysis). Despite being up to 56 times faster than existing open source systems, Neurobiber replicates classic MDA insights on the CORE corpus and achieves competitive performance on the PAN 2020 authorship verification task without extensive retraining. Its efficient and interpretable representations readily integrate into downstream NLP pipelines, facilitating large-scale stylometric research, forensic analysis, and real-time text monitoring. All components are made publicly available.
Tokenization is Sensitive to Language Variation
Feb 21, 2025Variation in language is ubiquitous and often systematically linked to regional, social, and contextual factors. Tokenizers split texts into smaller units and might behave differently for less common linguistic forms. This might affect downstream LLM performance differently on two types of tasks: Tasks where the model should be robust to language variation (e.g., for semantic tasks like NLI, labels do not depend on whether a text uses British or American spelling) and tasks where the model should be sensitive to language variation (e.g., for form-based tasks like authorship verification, labels depend on whether a text uses British or American spelling). We pre-train BERT base models for the popular Byte-Pair Encoding algorithm to investigate how key algorithmic design choices impact downstream models' performances: fitting corpus, pre-tokenizer and vocabulary size. We find that the best tokenizer varies on the two task types -- with the pre-tokenizer having the biggest impact on performance. Further, we introduce a new approach to estimate tokenizer impact on downstream LLM performance, showing significant improvement over techniques like R\'enyi efficiency. We encourage more work on language variation and its relation to tokenizers and thus LLM performance.
What's Mine becomes Yours: Defining, Annotating and Detecting Context-Dependent Paraphrases in News Interview Dialogs
Apr 10, 2024Best practices for high conflict conversations like counseling or customer support almost always include recommendations to paraphrase the previous speaker. Although paraphrase classification has received widespread attention in NLP, paraphrases are usually considered independent from context, and common models and datasets are not applicable to dialog settings. In this work, we investigate paraphrases in dialog (e.g., Speaker 1: "That book is mine." becomes Speaker 2: "That book is yours."). We provide an operationalization of context-dependent paraphrases, and develop a training for crowd-workers to classify paraphrases in dialog. We introduce a dataset with utterance pairs from NPR and CNN news interviews annotated for context-dependent paraphrases. To enable analyses on label variation, the dataset contains 5,581 annotations on 600 utterance pairs. We present promising results with in-context learning and with token classification models for automatic paraphrase detection in dialog.
Same Author or Just Same Topic? Towards Content-Independent Style Representations
Apr 11, 2022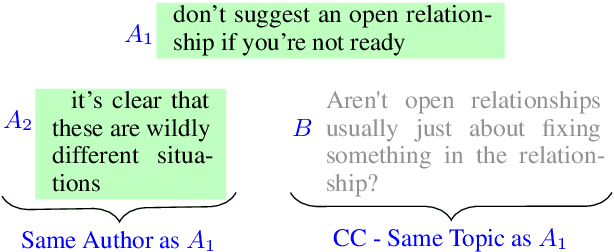
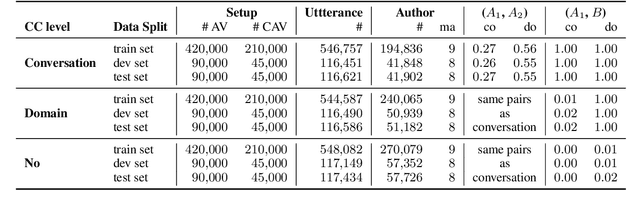
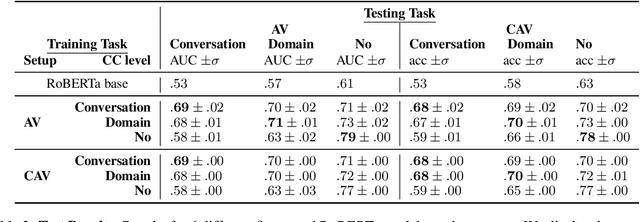

Linguistic style is an integral component of language. Recent advances in the development of style representations have increasingly used training objectives from authorship verification (AV): Do two texts have the same author? The assumption underlying the AV training task (same author approximates same writing style) enables self-supervised and, thus, extensive training. However, a good performance on the AV task does not ensure good "general-purpose" style representations. For example, as the same author might typically write about certain topics, representations trained on AV might also encode content information instead of style alone. We introduce a variation of the AV training task that controls for content using conversation or domain labels. We evaluate whether known style dimensions are represented and preferred over content information through an original variation to the recently proposed STEL framework. We find that representations trained by controlling for conversation are better than representations trained with domain or no content control at representing style independent from content.
Does It Capture STEL? A Modular, Similarity-based Linguistic Style Evaluation Framework
Sep 10, 2021

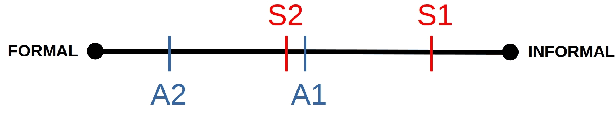
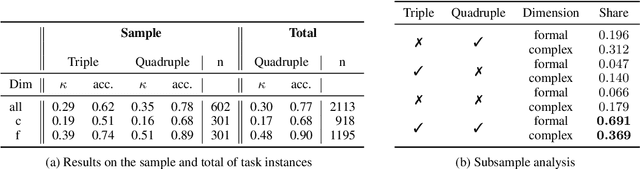
Style is an integral part of natural language. However, evaluation methods for style measures are rare, often task-specific and usually do not control for content. We propose the modular, fine-grained and content-controlled similarity-based STyle EvaLuation framework (STEL) to test the performance of any model that can compare two sentences on style. We illustrate STEL with two general dimensions of style (formal/informal and simple/complex) as well as two specific characteristics of style (contrac'tion and numb3r substitution). We find that BERT-based methods outperform simple versions of commonly used style measures like 3-grams, punctuation frequency and LIWC-based approaches. We invite the addition of further tasks and task instances to STEL and hope to facilitate the improvement of style-sensitive measures.