 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASReview: Open Source Software for Efficient and Transparent Active Learning for Systematic Reviews
Jun 22, 2020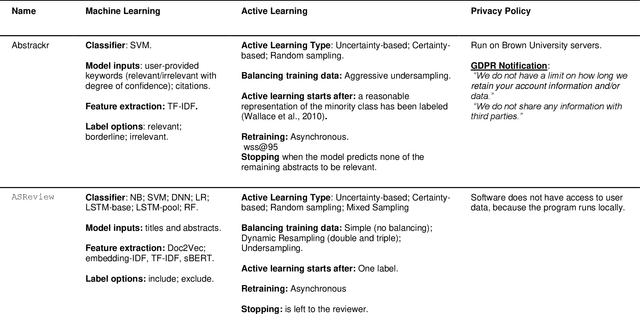
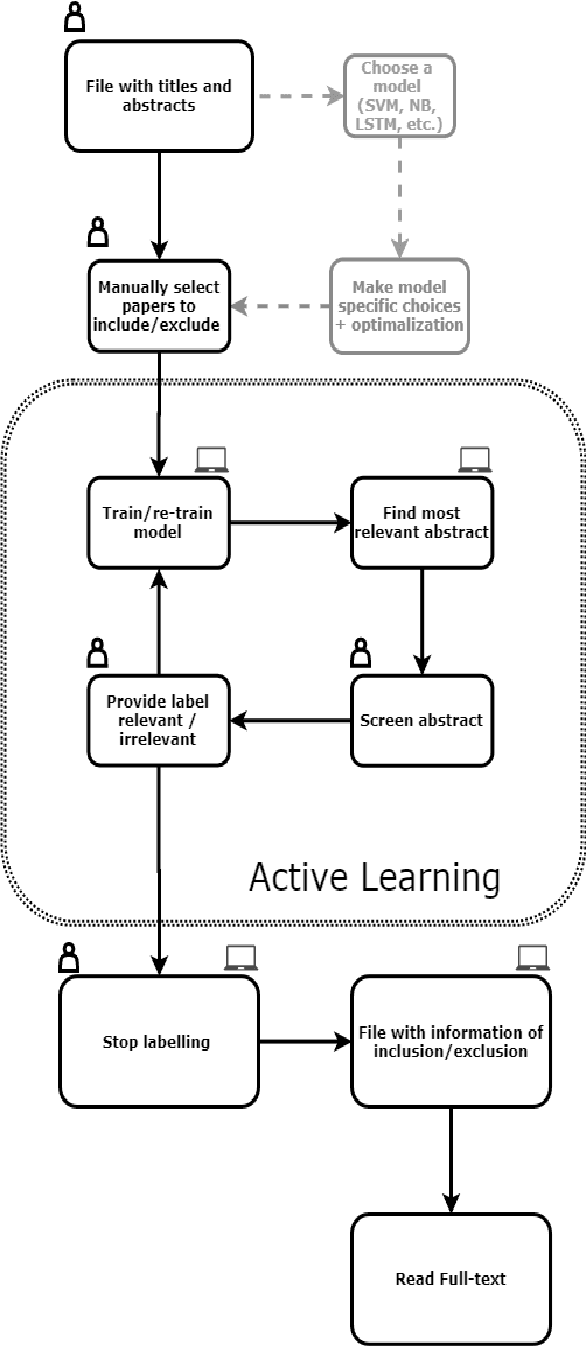

For many tasks -- including guideline development for medical doctors and systematic reviews for research fields -- the scientific literature needs to be checked systematically. The current practice is that scholars and practitioners screen thousands of studies by hand to find which studies to include in their review. This is error prone and inefficient. We therefore developed an open source machine learning (ML)-aided pipeline: Active learning for Systematic Reviews (ASReview). We show that by using active learning, ASReview can lead to far more efficient reviewing than manual reviewing, while exhibiting adequate quality. Furthermore, the presented software is fully transparent and open source.
The Data Representativeness Criterion: Predicting the Performance of Supervised Classification Based on Data Set Similarity
Feb 27, 2020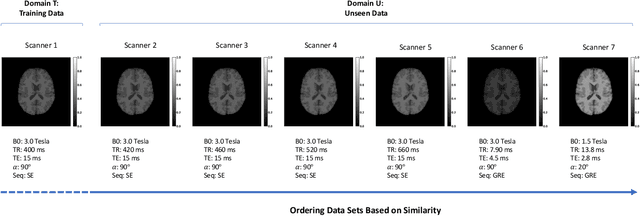
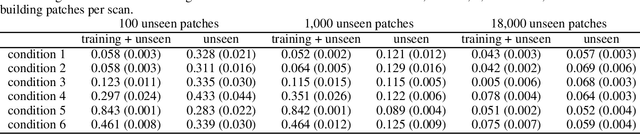
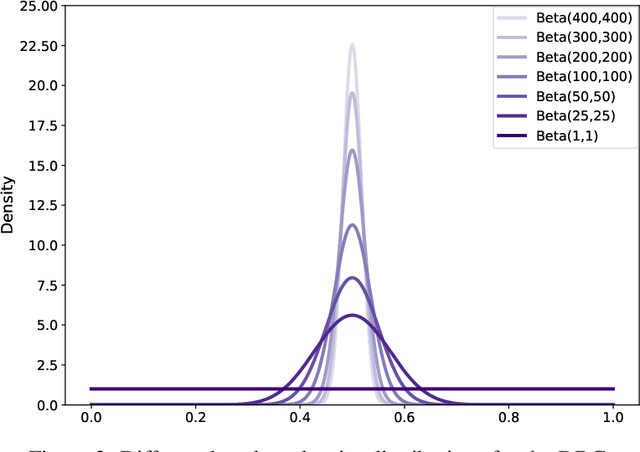
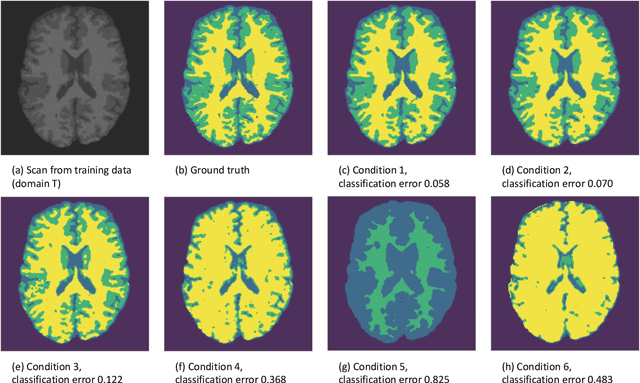
In a broad range of fields it may be desirable to reuse a supervised classification algorithm and apply it to a new data set. However, generalization of such an algorithm and thus achieving a similar classification performance is only possible when the training data used to build the algorithm is similar to new unseen data one wishes to apply it to. It is often unknown in advance how an algorithm will perform on new unseen data, being a crucial reason for not deploying an algorithm at all. Therefore, tools are needed to measure the similarity of data sets. In this paper, we propose the Data Representativeness Criterion (DRC) to determine how representative a training data set is of a new unseen data set. We present a proof of principle, to see whether the DRC can quantify the similarity of data sets and whether the DRC relates to the performance of a supervised classification algorithm. We compared a number of magnetic resonance imaging (MRI) data sets, ranging from subtle to severe difference is acquisition parameters. Results indicate that, based on the similarity of data sets, the DRC is able to give an indication as to when the performance of a supervised classifier decreases. The strictness of the DRC can be set by the user, depending on what one considers to be an acceptable underperformance.