 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule-Guided Feedback: Enhancing Reasoning by Enforcing Rule Adherence in Large Language Models
Mar 14, 2025



In this paper, we introduce Rule-Guided Feedback (RGF), a framework designed to enhance Large Language Model (LLM) performance through structured rule adherence and strategic information seeking. RGF implements a teacher-student paradigm where rule-following is forced through established guidelines. Our framework employs a Teacher model that rigorously evaluates each student output against task-specific rules, providing constructive guidance rather than direct answers when detecting deviations. This iterative feedback loop serves two crucial purposes: maintaining solutions within defined constraints and encouraging proactive information seeking to resolve uncertainties. We evaluate RGF on diverse tasks including Checkmate-in-One puzzles, Sonnet Writing, Penguins-In-a-Table classification, GSM8k, and StrategyQA. Our findings suggest that structured feedback mechanisms can significantly enhance LLMs' performance across various domains.
RESPONSE: Benchmarking the Ability of Language Models to Undertake Commonsense Reasoning in Crisis Situation
Mar 14, 2025



An interesting class of commonsense reasoning problems arises when people are faced with natural disasters. To investigate this topic, we present \textsf{RESPONSE}, a human-curated dataset containing 1789 annotated instances featuring 6037 sets of questions designed to assess LLMs' commonsense reasoning in disaster situations across different time frames. The dataset includes problem descriptions, missing resources, time-sensitive solutions, and their justifications, with a subset validated by environmental engineers. Through both automatic metrics and human evaluation, we compare LLM-generated recommendations against human responses. Our findings show that even state-of-the-art models like GPT-4 achieve only 37\% human-evaluated correctness for immediate response actions, highlighting significant room for improvement in LLMs' ability for commonsense reasoning in crises.
IAO Prompting: Making Knowledge Flow Explicit in LLMs through Structured Reasoning Templates
Feb 05, 2025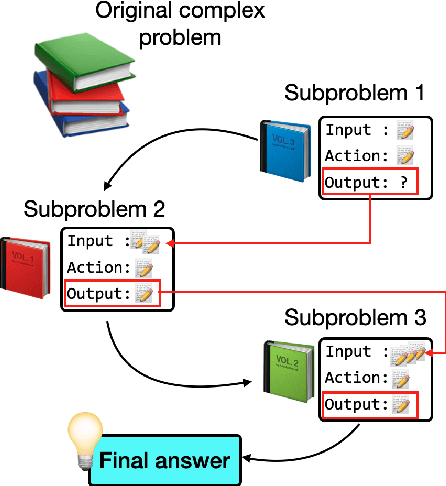



While Large Language Models (LLMs) demonstrate impressive reasoning capabilities, understanding and validating their knowledge utilization remains challenging. Chain-of-thought (CoT) prompting partially addresses this by revealing intermediate reasoning steps, but the knowledge flow and application remain implicit. We introduce IAO (Input-Action-Output) prompting, a structured template-based method that explicitly models how LLMs access and apply their knowledge during complex reasoning tasks. IAO decomposes problems into sequential steps, each clearly identifying the input knowledge being used, the action being performed, and the resulting output. This structured decomposition enables us to trace knowledge flow, verify factual consistency, and identify potential knowledge gaps or misapplications. Through experiments across diverse reasoning tasks, we demonstrate that IAO not only improves zero-shot performance but also provides transparency in how LLMs leverage their stored knowledge. Human evaluation confirms that this structured approach enhances our ability to verify knowledge utilization and detect potential hallucinations or reasoning errors. Our findings provide insights into both knowledge representation within LLMs and methods for more reliable knowledge application.
Unsupervised Learning of Graph from Recipes
Jan 22, 2024Cooking recipes are one of the most readily available kinds of procedural text. They consist of natural language instructions that can be challenging to interpret. In this paper, we propose a model to identify relevant information from recipes and generate a graph to represent the sequence of actions in the recipe. In contrast with other approaches, we use an unsupervised approach. We iteratively learn the graph structure and the parameters of a $\mathsf{GNN}$ encoding the texts (text-to-graph) one sequence at a time while providing the supervision by decoding the graph into text (graph-to-text) and comparing the generated text to the input. We evaluate the approach by comparing the identified entities with annotated datasets, comparing the difference between the input and output texts, and comparing our generated graphs with those generated by state of the art methods.
PizzaCommonSense: Learning to Model Commonsense Reasoning about Intermediate Steps in Cooking Recipes
Jan 12, 2024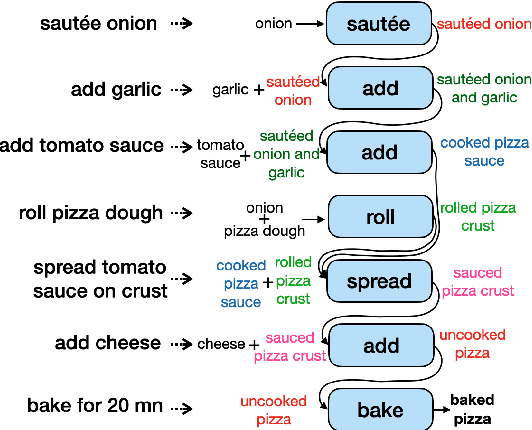
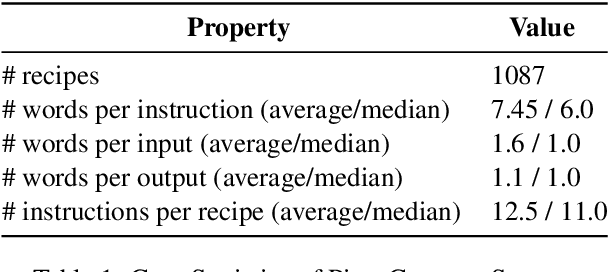
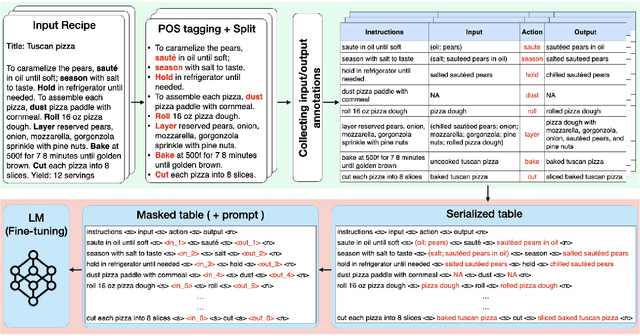

Decoding the core of procedural texts, exemplified by cooking recipes, is crucial for intelligent reasoning and instruction automation. Procedural texts can be comprehensively defined as a sequential chain of steps to accomplish a task employing resources. From a cooking perspective, these instructions can be interpreted as a series of modifications to a food preparation, which initially comprises a set of ingredients. These changes involve transformations of comestible resources. For a model to effectively reason about cooking recipes, it must accurately discern and understand the inputs and outputs of intermediate steps within the recipe. Aiming to address this, we present a new corpus of cooking recipes enriched with descriptions of intermediate steps of the recipes that explicate the input and output for each step. We discuss the data collection process, investigate and provide baseline models based on T5 and GPT-3.5. This work presents a challenging task and insight into commonsense reasoning and procedural text generation.
A Graphical Formalism for Commonsense Reasoning with Recipes
Jun 15, 2023



Whilst cooking is a very important human activity, there has been little consideration given to how we can formalize recipes for use in a reasoning framework. We address this need by proposing a graphical formalization that captures the comestibles (ingredients, intermediate food items, and final products), and the actions on comestibles in the form of a labelled bipartite graph. We then propose formal definitions for comparing recipes, for composing recipes from subrecipes, and for deconstructing recipes into subrecipes. We also introduce and compare two formal definitions for substitution into recipes which are required when there are missing ingredients, or some actions are not possible, or because there is a need to change the final product somehow.
Unsupervised Alignment of Distributional Word Embeddings
Mar 09, 2022


Cross-domain alignment play a key roles in tasks ranging from machine translation to transfer learning. Recently, purely unsupervised methods operating on monolingual embeddings have successfully been used to infer a bilingual lexicon without relying on supervision. However, current state-of-the art methods only focus on point vectors although distributional embeddings have proven to embed richer semantic information when representing words. In this paper, we propose stochastic optimization approach for aligning probabilistic embeddings. Finally, we evaluate our method on the problem of unsupervised word translation, by aligning word embeddings trained on monolingual data. We show that the proposed approach achieves good performance on the bilingual lexicon induction task across several language pairs and performs better than the point-vector based approach.
Learning Analogy-Preserving Sentence Embeddings for Answer Selection
Oct 11, 2019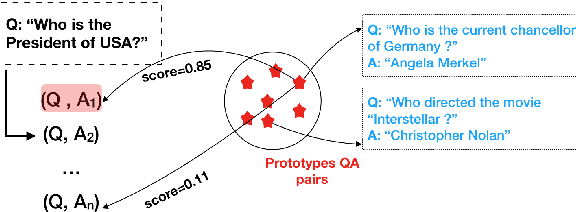

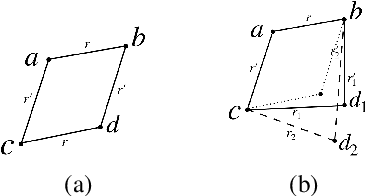
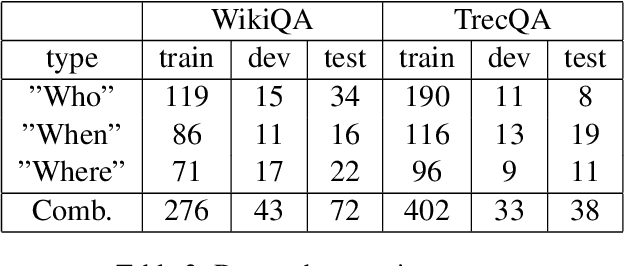
Answer selection aims at identifying the correct answer for a given question from a set of potentially correct answers. Contrary to previous works, which typically focus on the semantic similarity between a question and its answer, our hypothesis is that question-answer pairs are often in analogical relation to each other. Using analogical inference as our use case, we propose a framework and a neural network architecture for learning dedicated sentence embeddings that preserve analogical properties in the semantic space. We evaluate the proposed method on benchmark datasets for answer selection and demonstrate that our sentence embeddings indeed capture analogical properties better than conventional embeddings, and that analogy-based question answering outperforms a comparable similarity-based technique.