 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Guided Inverse Reinforcement Learning Under Partial Information
Paper and Code
May 28, 2021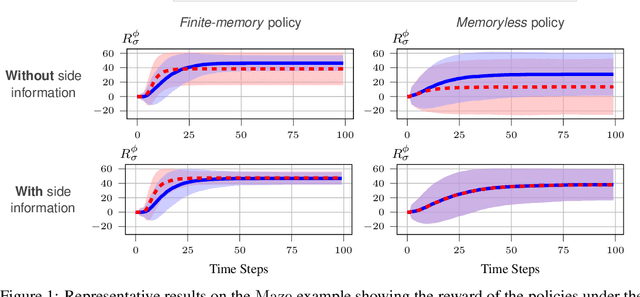
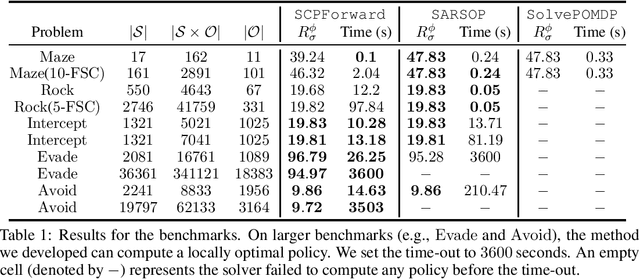
We study the problem of inverse reinforcement learning (IRL), where the learning agent recovers a reward function using expert demonstrations. Most of the existing IRL techniques make the often unrealistic assumption that the agent has access to full information about the environment. We remove this assumption by developing an algorithm for IRL in partially observable Markov decision processes (POMDPs), where an agent cannot directly observe the current state of the POMDP. The algorithm addresses several limitations of existing techniques that do not take the \emph{information asymmetry} between the expert and the agent into account. First, it adopts causal entropy as the measure of the likelihood of the expert demonstrations as opposed to entropy in most existing IRL techniques and avoids a common source of algorithmic complexity. Second, it incorporates task specifications expressed in temporal logic into IRL. Such specifications may be interpreted as side information available to the learner a priori in addition to the demonstrations, and may reduce the information asymmetry between the expert and the agent. Nevertheless, the resulting formulation is still nonconvex due to the intrinsic nonconvexity of the so-called \emph{forward problem}, i.e., computing an optimal policy given a reward function, in POMDPs. We address this nonconvexity through sequential convex programming and introduce several extensions to solve the forward problem in a scalable manner. This scalability allows computing policies that incorporate memory at the expense of added computational cost yet also achieves higher performance compared to memoryless policies. We demonstrate that, even with severely limited data, the algorithm learns reward functions and policies that satisfy the task and induce a similar behavior to the expert by leveraging the side information and incorporating memory into the policy.