 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Uncertainty Quantification through Directional Entailment Graph and Claim Level Response Augmentation
Paper and Code


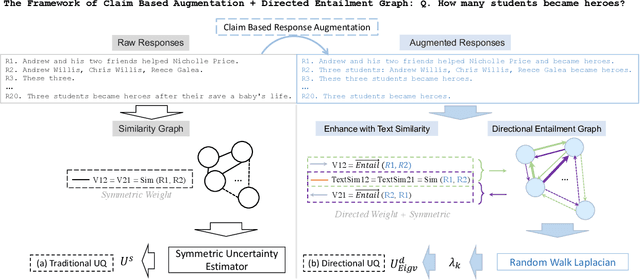

The Large language models (LLMs) have showcased superior capabilities in sophisticated tasks across various domains, stemming from basic question-answer (QA), they are nowadays used as decision assistants or explainers for unfamiliar content. However, they are not always correct due to the data sparsity in specific domain corpus, or the model's hallucination problems. Given this, how much should we trust the responses from LLMs? This paper presents a novel way to evaluate the uncertainty that captures the directional instability, by constructing a directional graph from entailment probabilities, and we innovatively conduct Random Walk Laplacian given the asymmetric property of a constructed directed graph, then the uncertainty is aggregated by the derived eigenvalues from the Laplacian process. We also provide a way to incorporate the existing work's semantics uncertainty with our proposed layer. Besides, this paper identifies the vagueness issues in the raw response set and proposes an augmentation approach to mitigate such a problem, we conducted extensive empirical experiments and demonstrated the superiority of our proposed solutions.