 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture Slot Prediction for Unsupervised Object Discovery in Surgical Video
Jul 02, 2025Object-centric slot attention is an emerging paradigm for unsupervised learning of structured, interpretable object-centric representations (slots). This enables effective reasoning about objects and events at a low computational cost and is thus applicable to critical healthcare applications, such as real-time interpretation of surgical video. The heterogeneous scenes in real-world applications like surgery are, however, difficult to parse into a meaningful set of slots. Current approaches with an adaptive slot count perform well on images, but their performance on surgical videos is low. To address this challenge, we propose a dynamic temporal slot transformer (DTST) module that is trained both for temporal reasoning and for predicting the optimal future slot initialization. The model achieves state-of-the-art performance on multiple surgical databases, demonstrating that unsupervised object-centric methods can be applied to real-world data and become part of the common arsenal in healthcare applications.
Disentangling spatio-temporal knowledge for weakly supervised object detection and segmentation in surgical video
Jul 23, 2024

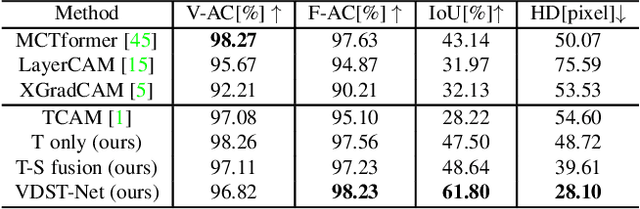
Weakly supervised video object segmentation (WSVOS) enables the identification of segmentation maps without requiring an extensive training dataset of object masks, relying instead on coarse video labels indicating object presence. Current state-of-the-art methods either require multiple independent stages of processing that employ motion cues or, in the case of end-to-end trainable networks, lack in segmentation accuracy, in part due to the difficulty of learning segmentation maps from videos with transient object presence. This limits the application of WSVOS for semantic annotation of surgical videos where multiple surgical tools frequently move in and out of the field of view, a problem that is more difficult than typically encountered in WSVOS. This paper introduces Video Spatio-Temporal Disentanglement Networks (VDST-Net), a framework to disentangle spatiotemporal information using semi-decoupled knowledge distillation to predict high-quality class activation maps (CAMs). A teacher network designed to resolve temporal conflicts when specifics about object location and timing in the video are not provided works with a student network that integrates information over time by leveraging temporal dependencies. We demonstrate the efficacy of our framework on a public reference dataset and on a more challenging surgical video dataset where objects are, on average, present in less than 60\% of annotated frames. Our method outperforms state-of-the-art techniques and generates superior segmentation masks under video-level weak supervision.
Data Stream Stabilization for Optical Coherence Tomography Volumetric Scanning
Dec 02, 2021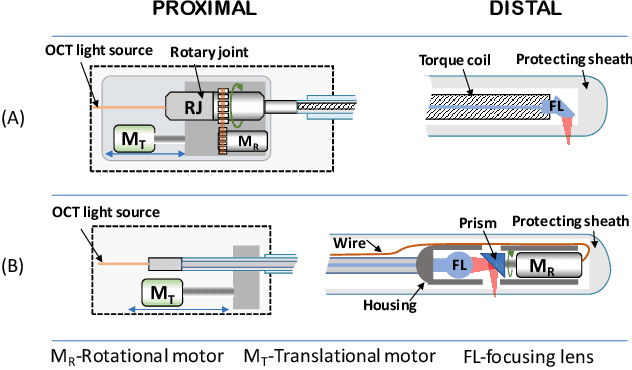
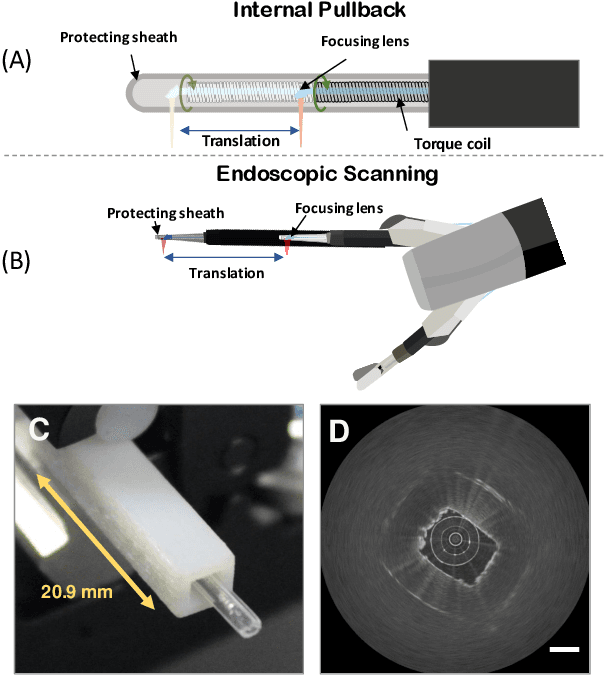
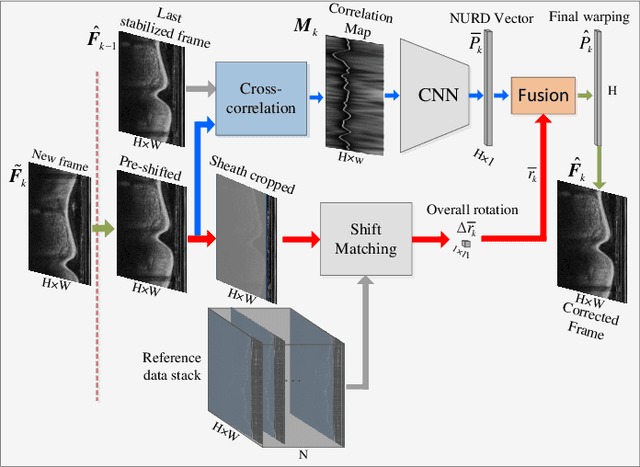

Optical Coherence Tomography (OCT) is an emerging medical imaging modality for luminal organ diagnosis. The non-constant rotation speed of optical components in the OCT catheter tip causes rotational distortion in OCT volumetric scanning. By improving the scanning process, this instability can be partially reduced. To further correct the rotational distortion in the OCT image, a volumetric data stabilization algorithm is proposed. The algorithm first estimates the Non-Uniform Rotational Distortion (NURD) for each B-scan by using a Convolutional Neural Network (CNN). A correlation map between two successive B-scans is computed and provided as input to the CNN. To solve the problem of accumulative error in iterative frame stream processing, we deploy an overall rotation estimation between reference orientation and actual OCT image orientation. We train the network with synthetic OCT videos by intentionally adding rotational distortion into real OCT images. As part of this article we discuss the proposed method in two different scanning modes: the first is a conventional pullback mode where the optical components move along the protection sheath, and the second is a self-designed scanning mode where the catheter is globally translated by using an external actuator. The efficiency and robustness of the proposed method are evaluated with synthetic scans as well as real scans under two scanning modes.
* 11pages, 5 figures